LLM Construction
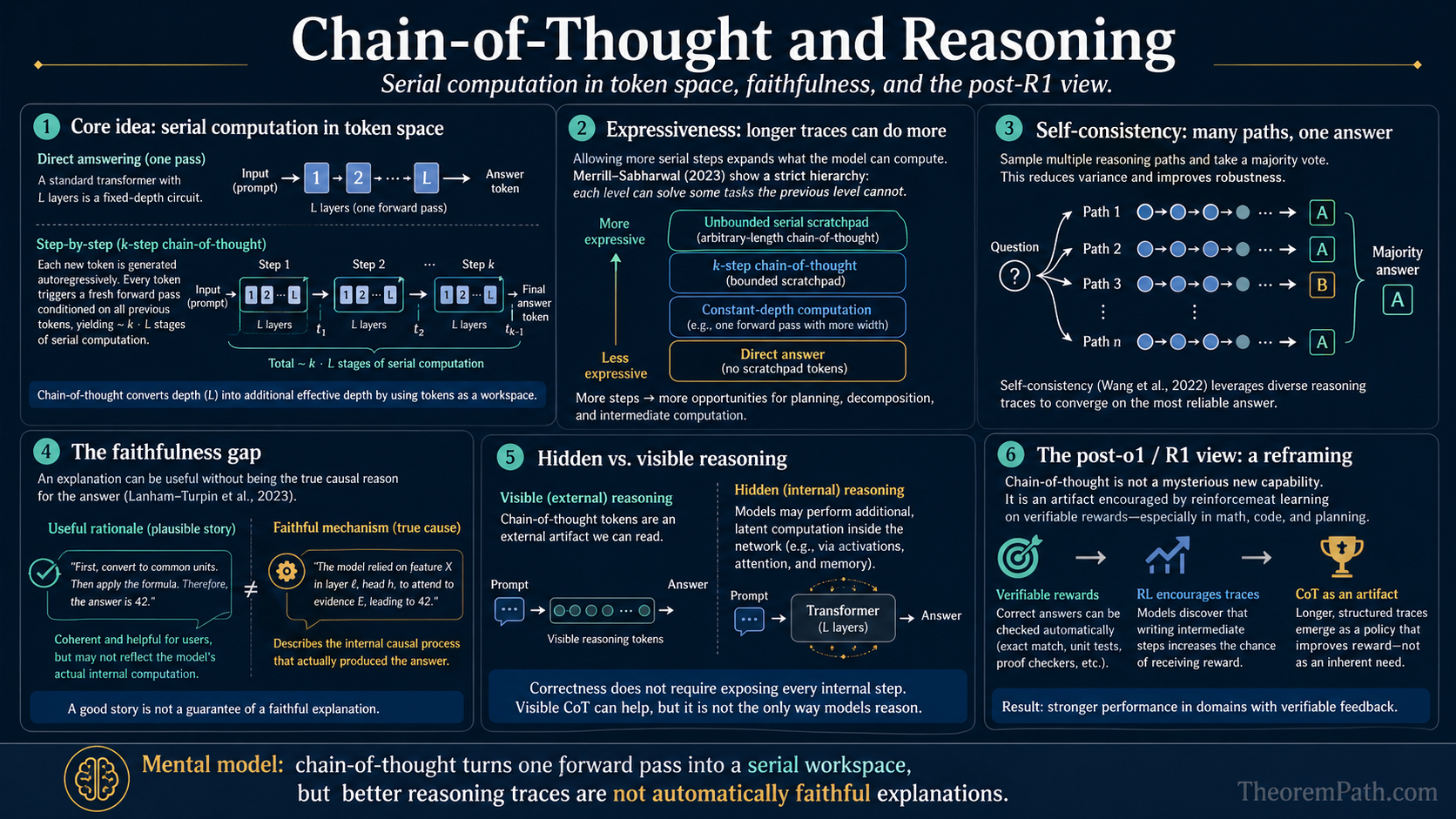
Chain-of-Thought and Reasoning
Chain-of-thought as serial computation in token-space: the Merrill-Sabharwal expressiveness hierarchy, the Lanham-Turpin faithfulness gap, self-consistency bounds, hidden CoT, and the post-o1/R1 reframing where CoT is the artifact of RL on verifiable rewards.
Prerequisites
Why This Matters
A standard transformer is a fixed-depth circuit. With layers, every output token is a function of the input that uses at most stages of serial composition, regardless of how complicated the underlying problem is. That ceiling is the reason direct prompting fails on multi-step problems even when the model "knows" each individual step.
Hide overviewShow overview
Standard prompting vs chain-of-thought; GSM8K accuracy on PaLM 540B (Wei et al. 2022)
Chain-of-thought (CoT) prompting breaks the ceiling by writing intermediate tokens to the context window. Each generated token is a fresh forward pass conditioned on every prior token, so a -token chain is roughly stages of serial computation. Merrill and Sabharwal (2023) proved this informal picture: with enough CoT steps a transformer recognizes exactly the polynomial-time languages.
Three things follow that this page treats as first-class:
- Expressiveness. A formal hierarchy ( without CoT, regular languages with linear CoT, with polynomial CoT) tells you what tasks CoT can possibly help on.
- Faithfulness. The text the model writes is not necessarily the computation the model runs. Lanham et al. (2023) and Turpin et al. (2023) measured the gap, with consequences for safety and interpretability.
- Reframing after o1 and R1. Post-2024 reasoning models (o1, DeepSeek R1) reach long-CoT behavior through RL on verifiable rewards, not through prompt engineering. The page ends on what that changes and what stays the same.
Chain-of-Thought Prompting
Chain-of-Thought Prompting
A prompting strategy where the model is instructed (or given few-shot examples) to produce intermediate reasoning steps before the final answer. The prompt includes examples of the form: question, step-by-step reasoning, answer.
Wei et al. (2022) showed that adding "Let's think step by step" or providing few-shot exemplars with reasoning chains improved accuracy on GSM8K (math word problems) from ~18% to ~57% for PaLM 540B. Kojima et al. (2022) showed that even the bare zero-shot trigger phrase elicits structured reasoning in sufficiently large models. Below roughly 60-100B parameters the trigger frequently produces fluent-but-wrong chains, an early empirical hint that CoT depends on a base of in-context-learning competence.
Why it works (mechanistic view). Each intermediate token conditions the next generation step. Without CoT, the model must compute the answer in a single forward pass, which means the "reasoning" is limited to the depth of the network. With CoT, the model can perform serial computation across multiple token-generation steps. Each step is a forward pass, so reasoning tokens give the model additional "layers" of serial computation. The next section makes this precise as a complexity-class statement.
CoT as Problem Decomposition
Statement
If a task can be decomposed into subtasks where each is solvable by the model in a single forward pass, then CoT prompting that elicits solutions to sequentially enables the model to solve by conditioning each step on the outputs of previous steps. Without CoT, the model must solve the composed task in a single forward pass, which may exceed its computational capacity.
Intuition
A transformer has fixed depth. Each forward pass computes a function of bounded complexity. Multi-step problems exceed this complexity. CoT converts a deep computation into a sequence of shallow computations, where each step's output is written to the context window and read by subsequent steps. The context window acts as an external memory or scratchpad.
Proof Sketch
Feng et al. (2023) formalized this: constant-depth transformers cannot solve problems requiring sequential computation steps (e.g., composition of functions). However, with intermediate generation steps, each step is a constant-depth computation, and the full chain composes such steps. This is analogous to the difference between (constant-depth circuits) and (polynomial-time computation).
Why It Matters
This explains why CoT helps specifically on compositional tasks (multi-step math, multi-hop reasoning) but provides little benefit on tasks that are already within single-step capacity (sentiment classification, factual recall). The benefit scales with the number of reasoning steps required.
Failure Mode
CoT only helps if the model can execute each individual step correctly. If a single step requires knowledge or reasoning beyond the model's capacity, the chain fails. Errors also compound: an error in step propagates to all subsequent steps. For steps with per-step error probability , and assuming errors at different steps are independent, the probability of a fully correct chain is . In practice the independence assumption fails: errors cascade (a wrong intermediate claim biases later reasoning), so the true probability of a correct chain is typically lower than the product form suggests.
The Expressiveness Hierarchy
The proposition above is informal about "computational capacity." Merrill and Sabharwal (2023, 2024) made it sharp. Their model is a transformer decoder with bounded-precision attention; "no CoT" means decoding the answer in a fixed number of output tokens, " CoT" means producing up to intermediate tokens before the answer on inputs of length .
CoT Expressiveness Hierarchy (Merrill-Sabharwal)
Statement
Let denote the class of formal languages decidable by a fixed-precision transformer decoder allowed chain-of-thought tokens on inputs of length . Then:
- No CoT. . Standard transformers without intermediate generation cannot decide problems hard for under standard complexity assumptions; in particular they cannot decide undirected graph connectivity, finite-state-machine simulation, or -word problems.
- Logarithmic CoT. (logspace), only modestly above .
- Linear CoT. With projected pre-norm, contains all regular languages and is contained in the context-sensitive languages.
- Polynomial CoT. With generalized pre-norm, . Transformer decoders with polynomially many CoT tokens recognize exactly the polynomial-time languages.
Intuition
The depth of a transformer is the number of layers , and does not grow with input length. Without intermediate generation, the model is a fixed-depth circuit. Bounded-precision transformers without CoT sit inside uniform (Merrill, Sabharwal, Saunshi 2022). does contain parity and (uniform) iterated multiplication, so the relevant lower bounds are problems hard for (e.g., -word problems, regular-language membership in non-aperiodic languages, undirected graph connectivity), which provably cannot decide under standard complexity assumptions. Each generated token is a new forward pass that can read every previous output, so CoT tokens give the decoder a working tape of length . A polynomial tape plus constant-depth transitions simulates a polynomial-time Turing machine.
Proof Sketch
The lower bounds restate prior tight characterizations: bounded-precision transformers without CoT are in uniform (Merrill, Sabharwal, Saunshi 2022). The upper bound for polynomial CoT is by simulation: a machine with tape of length can be simulated by a transformer that reads its prefix-of-tape from the context window and writes the next tape symbol as the next output token; the transition function is constant-depth and depends on a constant-size window of the tape, which fits in a fixed-depth attention block. The matching lower bound (every polynomial-CoT decoder is in ) is by counting: each forward pass is polynomial-time, and there are polynomially many of them.
Why It Matters
This puts a clean ceiling and a clean floor on what CoT can do. CoT can realize anything in that is outside , which includes most multi-step arithmetic, dynamic programming, planning, and graph search. CoT cannot realize anything outside : no amount of polynomial chain-length lets a transformer decide an -hard language exactly, absent additional resources like external tools or non-determinism. It also explains the empirical pattern in Wei et al. (2022): CoT helps most on tasks that have a serial-depth bottleneck, and almost not at all on tasks already solvable in constant depth (single-token classification, lookup).
Failure Mode
Three caveats. (a) The result is about what languages can be decided by some weight setting, not what a particular pretrained model has actually learned. A transformer that could in principle solve a problem with 10 CoT tokens may need 200 in practice, or fail to find the right chain at all. (b) The characterization assumes the decoder is allowed to write arbitrary symbols; if the vocabulary is too small or the decoding deterministic, the simulation shrinks. (c) The bounded-precision assumption is essential: with unbounded precision a single transformer block already becomes Turing-complete, which is a less informative model of real systems.
Self-Consistency
Self-Consistency Improves Over Single CoT
Statement
Sample independent chain-of-thought reasoning paths from the model using temperature . Extract the final answer from each chain and take the majority vote. If each chain has probability of reaching the correct answer and chains are conditionally independent given the prompt, the majority vote accuracy approaches 1 as at a rate given by Hoeffding's inequality (a standard concentration inequality):
Intuition
Different reasoning paths may make different errors. If errors are uncorrelated, the majority vote cancels them. This is an ensemble method applied to reasoning chains rather than models.
Proof Sketch
Each chain produces a Bernoulli random variable: correct with probability , incorrect with probability . The majority vote is correct if more than chains are correct. By Hoeffding's inequality applied to the sum of these Bernoulli variables, the probability of the majority being wrong decays exponentially in .
Why It Matters
Wang et al. (2023) showed self-consistency (SC) improves GSM8K accuracy from ~57% (single CoT) to ~74% with just 40 samples. The cost is linear in (you run forward passes), but no retraining is needed. SC is the simplest form of test-time compute scaling.
Failure Mode
The assumption is critical. If the model is more likely to reach a wrong answer than the right one, majority vote amplifies the error. Also, chains are not truly independent (they share the same model weights and prompt), so the effective is smaller than the nominal sample count. Correlated errors reduce the benefit of voting.
Faithfulness: Does CoT Reflect Reasoning?
The expressiveness theorem says CoT can implement serial computation. The faithfulness question is empirical: does the chain a model writes actually correspond to the computation it ran? If not, then CoT is decorative for interpretability and unreliable for safety, even when it improves accuracy.
The CoT Faithfulness Gap
Statement
Let be a model that produces a chain and an answer on prompt . Define a chain faithful if (i) causality: editing changes in proportion to the edit's relevance, (ii) early commitment absent: forcing the model to commit to an answer after a truncated chain does not match the full-chain answer except at near , and (iii) paraphrase invariance: rewording while preserving content does not change .
Lanham et al. (2023) tested these properties across eight reasoning benchmarks and observed three patterns:
- Variable causality. Faithfulness is task- and model-dependent. AQuA and LogiQA show high CoT dependence; ARC-Easy and OpenBookQA show low dependence (the model commits to the same answer with or without the chain).
- Inverse scaling. On most tasks, faithfulness decreases as the model gets larger. Larger models can solve more in a single forward pass, so the chain becomes less load-bearing.
- Filler tokens do not substitute for content. Replacing the chain with meaningless padding tokens of the same length does not recover full-chain accuracy. CoT is not just "more compute in token form"; the content matters, even when the model could in principle just use extra context.
Intuition
A larger model with a deeper effective circuit can compute the answer in tokens and then narrate a chain that justifies it. The narration is plausible but post-hoc. A smaller model that physically needs the chain to solve the problem cannot afford this; its written steps are closer to the actual computation. Faithfulness and capability are in tension because more capable models do more in latent space.
Proof Sketch
This is an empirical finding rather than a theorem; the support comes from controlled interventions in Lanham et al. (2023) and Turpin et al. (2023). Lanham et al. ran four interventions on each chain: (1) early answering (force an answer at token ), (2) adding mistakes (corrupt one step), (3) paraphrasing (rewrite the chain), (4) filler-token substitution. Turpin et al. introduced spurious biasing features (e.g., always-A in few-shot exemplars, demographically biased prompts) and measured whether the model verbalized them in its chain. Across 13 BIG-Bench Hard tasks, biasing features reduced GPT-3.5 and Claude 1.0 accuracy by up to ~36 percentage points while the chains almost never mentioned the bias.
Why It Matters
For interpretability and safety, this matters more than the accuracy gain. A safety case that says "we read the chain to detect dangerous reasoning" fails on any model where the chain is a post-hoc rationalization. A chain that confidently rationalizes a stereotype-aligned answer without naming the stereotype defeats the very property CoT was supposed to provide. Anthropic and OpenAI both treat unfaithful CoT as a research priority, separate from the question of whether CoT improves benchmarks.
Failure Mode
"Faithful" is not a single number. A chain can be faithful in the early-answering sense (the model genuinely needs all the tokens) and unfaithful in the bias-verbalization sense (it omits the cause of its answer). Lanham et al. found tasks where (i) holds and (ii) does not, and vice versa. A reader of a published faithfulness number should always check which intervention generated it.
Faithfulness is not the same as accuracy
A model can be more accurate because it offloads computation to the chain (faithful, content-bearing CoT) or despite the chain being post-hoc narration (unfaithful). The accuracy curve and the faithfulness curve can move in opposite directions with scale: larger Claude and GPT models have become more accurate while the chains have become less faithful on the same tasks.
Bias is reasoning the model does not write down
Turpin et al. (2023) showed that injecting "always answer A" into few-shot exemplars makes models systematically pick A and write justifications that never mention exemplar order. This is the same pathology as a model that absorbs a demographic stereotype from the prompt and produces a stereotyped answer with race-blind justification. The chain looks like reasoning. The mechanism is bias, and the chain hides it.
Tree of Thought
Tree of thought (ToT) generalizes CoT from a single linear chain to a tree of reasoning paths. At each step, the model generates multiple candidate continuations, evaluates them (using the model itself as an evaluator), and explores the most promising branches.
Tree of Thought
A reasoning framework where the model explores multiple reasoning paths organized as a tree. At each node, the model generates candidate next steps. A value function (often the model itself prompted to evaluate) scores each candidate. Search proceeds via breadth-first search, depth-first search, or beam search over the tree.
ToT explicitly trades more inference compute for better answers. For tasks requiring planning or backtracking (e.g., Game of 24, crossword puzzles), ToT significantly outperforms linear CoT because linear CoT commits to a single path and cannot recover from early mistakes.
From Prompted CoT to RL on Verifiable Rewards
CoT, self-consistency, and ToT are inference-time techniques applied to a model trained for next-token prediction. The class of "reasoning models" that appeared in 2024-2025 (OpenAI o1 and o3, DeepSeek R1, Gemini Deep Think, Claude with extended thinking) is not a prompting trick. They are fine-tuned with reinforcement learning so that producing a long internal chain is the behavior the policy converges to.
The training signal is what changed. RL with verifiable rewards (RLVR) replaces a learned reward model with a programmatic checker: a math problem has a correct numeric answer, a code problem has unit tests, a logic problem has a known solution. The model samples a chain, the checker scores the final answer, and an algorithm such as PPO or GRPO increases the probability of chains that lead to checker-confirmed answers. DeepSeek R1 (Guo et al. 2025) showed that this objective alone, applied to a strong base model, produces longer chains, self-correction, and "wait, let me reconsider" phrases without explicit demonstrations.
Three points are easy to confuse and worth separating:
- CoT prompting is necessary but not sufficient. A non-reasoning base model with CoT prompting still benefits from intermediate steps (the expressiveness theorem still applies), but it does not learn to allocate chain length to problem difficulty.
- Test-time compute scaling is real but verifier-bottlenecked. Snell et al. (2024) and Brown et al. (2024) document smooth power-law gains from sampling and search, but the gain saturates at the verifier's ceiling. RLVR works precisely because the verifier is exact.
- "Thinking longer" is not a free hyperparameter. R1-style models exhibit a roughly logarithmic accuracy gain with reasoning-token budget on math, but the curve flattens past a model-specific elbow. Forcing more tokens beyond that elbow degrades coherence rather than improving accuracy.
The deeper takeaway: CoT was originally a property of the prompt. After RLVR, CoT is a property of the trained policy. The expressiveness ceiling (Merrill-Sabharwal: with polynomial chain length) and the faithfulness gap (Lanham, Turpin) both still apply.
Hidden Reasoning
Quiet-STaR (Zelikman et al. 2024) takes the next step: rather than training a model to write its reasoning out, train it to insert silent "thought" tokens between every word of training text and rewards thoughts that improve the model's prediction of the next visible token.
Hidden Chain-of-Thought (Quiet-STaR)
At each token position during generation, the model emits a sequence of unrendered "thought" tokens before emitting the next visible token. Thoughts are sampled in parallel across positions for efficiency, and a REINFORCE-style update increases the probability of thought sequences that improve the model's likelihood on the subsequent visible tokens. The thoughts are discarded from the rendered output.
Quiet-STaR yields zero-shot gains without task-specific fine-tuning: GSM8K moves from 5.9% to 10.9% and CommonsenseQA from 36.3% to 47.2% on Mistral 7B base after Quiet-STaR pretraining (Zelikman et al. 2024).
This shifts the safety story considerably. With visible CoT, faithfulness is already fragile (Lanham et al., Turpin et al.); with hidden CoT, the internal reasoning is by construction not in the rendered output. Anthropic and OpenAI have both flagged hidden reasoning as a category that voids any "read the chain" interpretability strategy. Whether o1's summarized internal chain (the visible portion shown to users) is faithful to the hidden raw trace is itself an open question.
Common Confusions
CoT is not just showing work
The intermediate steps are not cosmetic. They provide genuine computational benefit by allowing the model to store and condition on intermediate results. A model forced to produce the answer token immediately after the question cannot access this serial computation pathway.
CoT does not make the model smarter
CoT does not add new knowledge or capabilities. It allows the model to use existing capabilities more effectively on multi-step problems. If the model cannot perform a single reasoning step correctly, CoT will not fix it.
Self-consistency requires the task to have a unique answer
Majority voting assumes answers can be compared for equality. For open-ended generation (summarization, creative writing), there is no single correct answer to vote on. Self-consistency is specific to tasks with verifiable discrete answers.
Polynomial CoT is not the same as solving NP-hard problems
The Merrill-Sabharwal result says polynomial CoT recognizes exactly , not . A polynomial-length chain cannot in general decide SAT correctly without an external solver. Reasoning-model demos that "solve" combinatorial puzzles do so within polynomial-time-tractable subcases, by heuristic search that may be wrong, or with tool calls. The expressiveness ceiling is real.
A longer chain is not always a more accurate chain
Both prompted CoT and RL-trained reasoning models exhibit a non-monotone relationship between chain length and accuracy past a model-specific elbow. Beyond that point, additional tokens introduce drift, repetition, and false self-corrections. Forcing very long chains via prompts like "think for 50 more steps" usually hurts.
o1-style training does not repeal pretraining
RLVR is applied on top of a strong base model. R1-Zero (DeepSeek's pure-RL ablation) showed reasoning emerges without SFT, but it still requires a base model that can generate coherent multi-step text. Pretraining quality remains the binding constraint; RL shapes the policy, it does not provide the underlying capability.
Exercises
Problem
A model answers a math problem correctly with probability using a single CoT chain. If you sample independent chains and take the majority vote, what is the upper bound on the probability of an incorrect majority answer (using Hoeffding's bound)?
Problem
Explain why a constant-depth transformer cannot compute the composition of arbitrary functions for unbounded , but a transformer with CoT (producing intermediate tokens) can. What computational complexity class corresponds to each case?
Problem
Design a faithfulness intervention that distinguishes "the model uses the chain as serial computation" from "the model post-hoc rationalizes a one-pass answer." Specify (a) the protocol, (b) the prediction under each hypothesis, (c) why filler-token substitution alone is insufficient.
Problem
Suppose you train a 7B base model with RLVR on math (verifiable reward, GRPO). Empirically the model learns to produce 5x longer chains than the base. Two hypotheses: (H1) the longer chains are causally responsible for the accuracy gain (more serial compute, in the Merrill-Sabharwal sense); (H2) the longer chains are stylistic, and the gain comes from the policy shifting probability mass toward correct final answers regardless of chain content. Design a controlled comparison that distinguishes them and state what observation would refute each.
References
Prompting and search:
- Wei et al., "Chain-of-Thought Prompting Elicits Reasoning in Large Language Models", NeurIPS (2022). arXiv:2201.11903
- Kojima et al., "Large Language Models are Zero-Shot Reasoners", NeurIPS (2022). arXiv:2205.11916
- Wang et al., "Self-Consistency Improves Chain of Thought Reasoning in Language Models", ICLR (2023). arXiv:2203.11171
- Yao et al., "Tree of Thoughts: Deliberate Problem Solving with Large Language Models", NeurIPS (2023). arXiv:2305.10601
Theory:
- Merrill & Sabharwal, "The Expressive Power of Transformers with Chain of Thought", ICLR (2024). arXiv:2310.07923
- Merrill & Sabharwal, "The Parallelism Tradeoff: Limitations of Log-Precision Transformers", TACL (2023). arXiv:2207.00729
- Feng et al., "Towards Revealing the Mystery Behind Chain of Thought: A Theoretical Perspective", NeurIPS (2023). arXiv:2305.15408
- Perez, Barcelo & Marinkovic, "Attention is Turing-Complete", JMLR (2021). arXiv:1901.03429
Faithfulness and hidden computation:
- Lanham et al. (Anthropic), "Measuring Faithfulness in Chain-of-Thought Reasoning" (2023). arXiv:2307.13702
- Turpin et al., "Language Models Don't Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting", NeurIPS (2023). arXiv:2305.04388
- Pfau, Merrill & Bowman, "Let's Think Dot by Dot: Hidden Computation in Transformer Language Models", COLM (2024). arXiv:2404.15758
Reasoning-model training and test-time compute:
- DeepSeek-AI (Guo et al.), "DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning" (2025). arXiv:2501.12948
- OpenAI, "Learning to Reason with LLMs" (2024). openai.com/index/learning-to-reason-with-llms
- Snell et al., "Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters" (2024). arXiv:2408.03314
- Brown et al., "Large Language Monkeys: Scaling Inference Compute with Repeated Sampling" (2024). arXiv:2407.21787
- Zelikman et al., "Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking", COLM (2024). arXiv:2403.09629
Next Topics
- DPO vs GRPO vs RL Reasoning — how RLVR-trained reasoning models are actually optimized
- Scaling Laws — for the test-time compute scaling axis and its trade-offs with training compute
- Hallucination Theory — for why RLVR on math does not extend cleanly to open-domain factuality
Last reviewed: April 19, 2026
Canonical graph
Required before and derived from this topic
These links come from prerequisite edges in the curriculum graph. Editorial suggestions are shown here only when the target page also cites this page as a prerequisite.
Required prerequisites
4- Scaling Lawslayer 4 · tier 1
- Decoding Strategieslayer 3 · tier 2
- Transformer Architecturelayer 4 · tier 2
- Prompt Engineering and In-Context Learninglayer 5 · tier 2
Derived topics
3- Hallucination Theorylayer 4 · tier 1
- DPO vs GRPO vs RL for Reasoninglayer 5 · tier 2
- Tool-Augmented Reasoninglayer 5 · tier 2
Graph-backed continuations