Mathematical Infrastructure
Fokker–Planck Equation
The deterministic PDE for the time-evolving density of an SDE. The bridge that lets you reason about Langevin samplers, diffusion models, and stochastic optimization in PDE language: stationary distributions become null spaces, mixing times become spectral gaps, score functions become drift-density couplings.
Prerequisites
Why This Matters
Solving an SDE gives you sample paths; solving its Fokker–Planck equation gives you the density of those paths at every time. For most ML applications you do not actually want one trajectory. You want to know what distribution your sampler is converging to, how fast it gets there, and whether any of that depends on a hyperparameter you can tune. Those are PDE questions, not SDE questions, and the Fokker–Planck equation is what turns one into the other.
Hide overviewShow overview
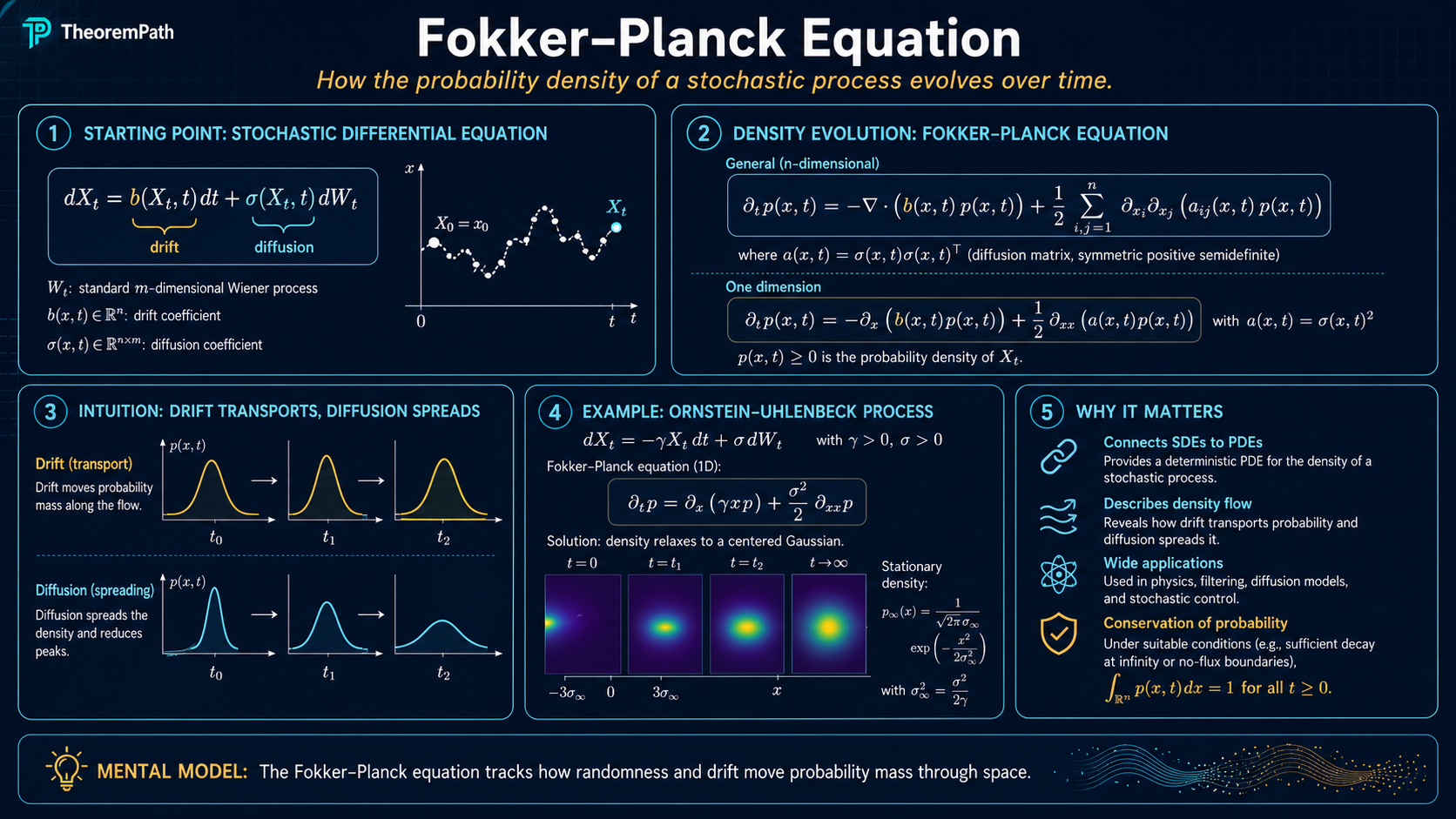
This is why the Fokker–Planck equation shows up implicitly under nearly every sampling and generative-modeling result in modern ML. The stationary density of Langevin dynamics is the kernel of its Fokker–Planck operator; the convergence rate of SGLD and ULA is the spectral gap of that operator; the forward noising process in diffusion models is a Fokker–Planck PDE evolving the data distribution toward standard Gaussian; the score-matching loss is a re-expression of one term in the Fokker–Planck operator.
The same equation also appears in physics (chemical kinetics, polymer dynamics, plasma transport), finance (option pricing under nonconstant volatility), and biology (population genetics under drift). It is one of the densest cross-disciplinary PDEs you can learn.
Mental Model
An SDE pushes a single particle around with drift and noise . If you instead release a cloud of independent particles all from the same initial distribution and watch their density evolve, that density satisfies a deterministic PDE: the drift advects the cloud, and the noise smears it. The Fokker–Planck equation is exactly this advection–diffusion PDE. The smearing is anisotropic and position-dependent because can be a matrix that varies with .
A useful aphorism: the SDE is the Lagrangian view (follow one particle), the Fokker–Planck equation is the Eulerian view (watch the field of particles). They contain the same information, expressed in dual languages.
Formal Derivation
Fokker–Planck Equation (Forward Kolmogorov)
Let solve the Itô SDE with , and suppose admits a smooth density . Then satisfies
with diffusion tensor , initial condition , and decay-at-infinity boundary conditions.
The right-hand side is the forward Kolmogorov operator . Its formal adjoint is the infinitesimal generator of the SDE.
Fokker–Planck Derivation from Itô
Statement
Under the assumptions above, for every test function and time , . Writing this as and integrating by parts gives as a distributional identity, which equals the Fokker–Planck equation in the display above.
Intuition
The generator is "what happens to the expectation of a function as the particle moves." Its adjoint flips the perspective: "what happens to the density as the cloud of particles moves." The Itô formula gives the first; integration by parts trades it for the second.
Proof Sketch
By Itô, . The stochastic integral is a martingale (test functions have compact support), so . Differentiating in and writing both sides as integrals against gives for every , which forces pointwise on the support.
Why It Matters
Every claim about "what distribution the SDE converges to" or "how fast it mixes" is, formally, a claim about . Spectral analysis of gives mixing rates; null-space analysis gives stationary distributions; positivity and mass-conservation properties live in the PDE. None of this is visible from the SDE itself. The density satisfies in the weak sense.
Failure Mode
The derivation assumes a smooth density exists. SDEs with degenerate or state-dependent diffusion (e.g., CIR near zero, hypoelliptic systems where is rank-deficient) may have singular or measure-valued solutions to the Fokker–Planck equation, requiring the framework of Hörmander's theorem or Malliavin calculus. The clean PDE form is restricted to elliptic / uniformly nondegenerate diffusions.
Stationary Distributions
A stationary density is a fixed point of the Fokker–Planck flow: . For the canonical "overdamped Langevin" SDE with potential and inverse temperature , the stationary distribution is the Gibbs measure
Plug it into and the drift and diffusion terms cancel exactly. This is the entire foundation of MCMC sampling from energy-based models, of SGLD as approximate Bayesian inference, and of the equilibrium statistical mechanics that generative models implicitly target.
For non-reversible SDEs (those with drift not equal to for any ), the stationary distribution still exists when has a one-dimensional kernel, but it is no longer Gibbs and the analysis is much harder.
Convergence Rates and Spectral Gap
The Fokker–Planck operator on is self-adjoint and negative semidefinite for reversible (Langevin) dynamics, with as a simple eigenvalue and eigenvector . The next eigenvalue controls exponential convergence:
The constant is the spectral gap, and Bakry–Émery theory gives sharp lower bounds in terms of the convexity of : for the overdamped Langevin SDE , if for some , then and the law of converges exponentially fast at rate . The temperature cancels: warmer noise (larger ) accelerates diffusion but the effective potential entering the stationary measure is , which has convexity , and these two effects exactly compensate. The OU process is the canonical sanity check: gives , and the Bakry–Émery bound predicts , which matches the exact spectrum below regardless of . This is the cleanest statement of "Langevin mixes fast on log-concave targets," and it is the theoretical underpinning of every convergence guarantee for gradient-based MCMC on convex problems.
The stronger log-Sobolev inequality
implies the same exponential rate in KL divergence, not just , and is the right tool whenever you need entropic — not energetic — convergence guarantees.
Worked Example: Ornstein–Uhlenbeck Density
Take in . The Fokker–Planck equation is . With Gaussian initial data the solution stays Gaussian with
The stationary distribution is , exactly the Gibbs measure for and . The spectral gap is — the same that controls mean-reversion in the SDE, so the SDE and PDE views agree on the convergence rate, as they must.
Common Confusions
Forward Kolmogorov vs backward Kolmogorov are different equations
The Fokker–Planck equation is the forward Kolmogorov equation: it evolves the density of forward in time. The backward Kolmogorov equation with terminal condition evolves the value function backward in time and uses the generator , not its adjoint. Forward asks "where will the particle be?", backward asks "what is the expected payoff if it ends here?". The Feynman–Kac formula and the deep BSDE method live in the backward picture.
The diffusion tensor is σσ^⊤, not σ
A common bug is to write the second derivative term as instead of . The diffusion enters the Fokker–Planck equation only through its covariance matrix ; two SDEs with the same drift and the same have the same Fokker–Planck equation, even if their matrices differ (e.g., differ by a right rotation). This is also why diffusion models can use scalar noise schedules without losing generality.
A stationary distribution is not the same as a steady-state flux
has two meaningful sub-cases. Reversible (Langevin) dynamics: drift and the equilibrium current is identically zero — the system is in detailed balance. Non-reversible dynamics: but ; the system has steady probability currents, only their divergence vanishes. Non-reversible Langevin samplers exploit exactly this to mix faster than reversible ones; they sit at a stationary distribution but with persistent rotational flow.
Exercises
Problem
Verify by direct substitution that the Gibbs measure is stationary for the overdamped Langevin SDE . Identify the cancellation that makes this work.
Problem
For the OU process , compute the full spectrum of the Fokker–Planck operator on . Show that the eigenvalues are for and identify the corresponding eigenfunctions.
References
Canonical:
- Risken, The Fokker–Planck Equation: Methods of Solution and Applications (2nd ed., Springer, 1989). The standard physics-flavored reference; Chapters 4-6 cover the canonical-form derivation, stationary solutions, and eigenfunction expansions.
- Karatzas and Shreve, Brownian Motion and Stochastic Calculus (2nd ed., Springer, 1991), Chapter 5.7. SDE-side derivation of the forward and backward Kolmogorov equations.
- Stroock and Varadhan, Multidimensional Diffusion Processes (Springer, 1979). Rigorous treatment of the martingale-problem formulation, useful when coefficients are non-smooth.
- Pavliotis, Stochastic Processes and Applications (Springer, 2014). Chapters 4 and 5 give the cleanest modern treatment, with explicit Bakry-Emery / log-Sobolev material in Chapter 6.
Current:
- Bakry, Gentil, and Ledoux, Analysis and Geometry of Markov Diffusion Operators (Springer Grundlehren, 2014). The authoritative reference on functional inequalities for diffusion semigroups; Chapters 4-6 give the curvature-dimension framework that yields exponential convergence.
- Villani, Optimal Transport: Old and New (Springer, 2009), Chapters 21-25. The Otto-calculus / gradient-flow viewpoint: Fokker-Planck as the Wasserstein gradient flow of relative entropy.
- Markowich and Villani, On the Trend to Equilibrium for the Fokker-Planck Equation: An Interplay Between Physics and Functional Analysis (Matematica Contemporanea 19, 2000). The reference paper on entropy methods for convergence rates.
Next Topics
- Langevin Dynamics: the canonical SDE whose Fokker–Planck equation has a Gibbs stationary distribution.
- Score Matching: training a network on the score that appears inside the Fokker–Planck operator.
- Diffusion Models: forward noising SDEs and their Fokker–Planck duals; reverse-time samplers.
- Time Reversal of SDEs: how the reversed SDE's drift involves the score that the forward Fokker–Planck operator already contains.
- SGD as SDE: SGD viewed as a discretization of a Langevin-type SDE; the implicit Fokker–Planck equation for SGD's stationary distribution.
Last reviewed: April 18, 2026
Canonical graph
Required before and derived from this topic
These links come from prerequisite edges in the curriculum graph. Editorial suggestions are shown here only when the target page also cites this page as a prerequisite.
Required prerequisites
4- Divergence, Curl, and Line Integralslayer 0A · tier 2
- PDE Fundamentals for Machine Learninglayer 1 · tier 2
- Feynman–Kac Formulalayer 3 · tier 2
- Stochastic Differential Equationslayer 3 · tier 2
Derived topics
6- Score Matchinglayer 3 · tier 1
- Diffusion Modelslayer 4 · tier 1
- Langevin Dynamicslayer 3 · tier 2
- Probability Flow ODElayer 3 · tier 2
- SGD as a Stochastic Differential Equationlayer 3 · tier 2
+1 more on the derived-topics page.