Learning Theory Core
Rademacher Complexity
A data-dependent measure of hypothesis class complexity that gives tighter generalization bounds than VC dimension by measuring how well the class can fit random noise on the actual data.
Prerequisites
Why This Matters
VC dimension gives you a single number describing the worst-case complexity of a hypothesis class. But it ignores the data distribution entirely. A class with VC dimension gets the same generalization bound whether the data is easy (large margin, low noise) or hard (adversarial).
Hide overviewShow overview
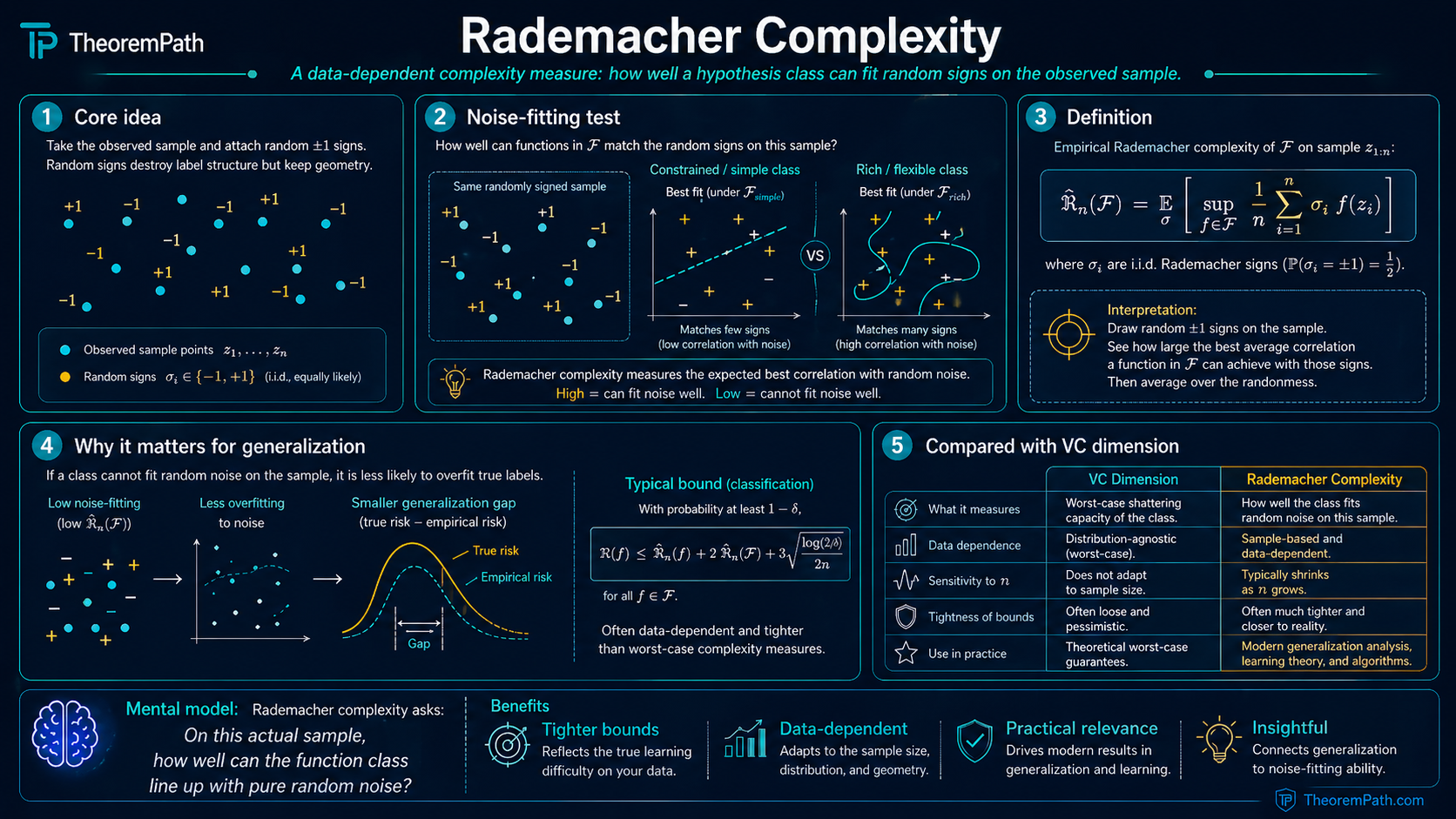
Rademacher complexity fixes this. It measures how well the hypothesis class can correlate with random noise on the actual data at hand. If the data has structure that limits how well hypotheses can fit noise, Rademacher complexity captures this and gives a tighter bound. This is why Rademacher complexity is the preferred complexity measure in modern learning theory when you want distribution-aware guarantees.
Mental Model
Imagine giving your hypothesis class a "noise-fitting test." Generate random labels (Rademacher variables) for your data points. Ask: how well can the best hypothesis in correlate with these random labels?
If the class can achieve high correlation with random noise, it is complex and overfitting-prone. If even the best hypothesis in the class achieves only weak correlation with noise, the class is simple and generalizes well.
This is a data-dependent test: the same class might score high on one dataset (where it has many effective degrees of freedom) and low on another (where the data geometry constrains it). VC dimension cannot distinguish these cases; Rademacher complexity can.
Formal Setup and Notation
Let be a class of real-valued functions (in learning theory, and is the loss composed with a hypothesis). Let be a sample, and let be i.i.d. Rademacher random variables: .
Empirical Rademacher Complexity
The empirical Rademacher complexity of with respect to sample is:
This measures the expected maximum correlation between the function class and random noise, evaluated on the specific sample . It is a random variable that depends on .
Rademacher Complexity
The (expected) Rademacher complexity of is:
This averages the empirical Rademacher complexity over all possible samples of size drawn from . It depends on both and the distribution , but not on any particular sample.
Rademacher Variables
A Rademacher random variable takes values and each with probability . Rademacher variables are symmetric around zero () and are used as "random labels" or "random signs" to test whether a function class can fit noise. The symmetry is what makes the symmetrization technique work.
Core Definitions
The empirical Rademacher complexity is the quantity that appears directly in generalization bounds. It has several important properties:
Data-dependence. Unlike VC dimension, depends on the specific sample . Two different datasets of the same size can yield different Rademacher complexities for the same hypothesis class.
Scale sensitivity. . Scaling the function class scales the complexity proportionally.
Monotonicity. If , then . Larger classes have higher Rademacher complexity.
Convex hull invariance. . Taking convex combinations does not increase Rademacher complexity, because the supremum of a linear functional over a convex set is attained at an extreme point.
Main Theorems
Rademacher Complexity Generalization Bound
Statement
Let be a class of functions and let be drawn i.i.d. from . Then for any , with probability at least over the draw of , simultaneously for all :
The two-sided version: with probability at least ,
The same bounds hold with replaced by (at the cost of a slightly modified confidence term).
Intuition
The generalization gap is controlled by two terms: (1) the Rademacher complexity, which measures how well can fit random noise. This is the "capacity" term, and (2) a confidence term from concentration. The factor of 2 in front of comes from the symmetrization technique (going from one-sample to two-sample and back).
If the Rademacher complexity is small, the class cannot overfit, so the empirical average is close to the population expectation for all simultaneously. which is exactly uniform convergence.
Proof Sketch
The proof has three steps:
Step 1: Symmetrization. For any fixed : .
The key idea: introduce a ghost sample and write . Then . Since and are exchangeable, swapping them with random signs does not change the distribution. This introduces the Rademacher variables.
Step 2: Concentration. The function satisfies bounded differences: changing one changes by at most . Apply McDiarmid's inequality to get .
Step 3: Combine. from Step 1. Add the concentration term from Step 2 with .
Why It Matters
This bound is the main reason Rademacher complexity is central to learning theory. It provides a uniform convergence guarantee with a complexity term that is:
- Data-dependent (through ): tighter on easy data
- Computable (in principle): you can estimate it by sampling Rademacher vectors
- Applicable to infinite classes: no need for finiteness or VC dimension
For the specific case of learning with a loss class , this gives for all simultaneously.
Failure Mode
The bound requires functions in (or bounded range). For unbounded losses, you need truncation arguments or sub-Gaussian assumptions. Also, the factor of 2 from symmetrization is not always tight. in some cases, local Rademacher complexity or peeling arguments can improve it.
Symmetrization Lemma
Statement
For any class of functions :
Intuition
The symmetrization lemma says: the expected uniform convergence gap is at most twice the Rademacher complexity. The factor of 2 arises because going from population to empirical involves introducing a ghost sample (one factor) and then replacing the ghost with Rademacher signs (which can only increase the supremum by symmetry arguments). This lemma is the core engine of the Rademacher approach.
Proof Sketch
Let be an independent copy of .
by Jensen's inequality (moving the expectation over inside the sup). Now . Since are exchangeable, multiplying each term by a random sign does not change the distribution:
The last step uses the triangle inequality and the fact that has the same distribution as .
Why It Matters
Symmetrization is the technique that connects the generalization gap (a quantity involving the unknown distribution ) to Rademacher complexity (a quantity that can be estimated from data). It is the same symmetrization technique used in the VC dimension proof, but here it is applied directly to the function class rather than going through the growth function.
Failure Mode
The factor of 2 can be suboptimal. For one-sided bounds (only the upper tail of the generalization gap), local Rademacher complexity techniques can sometimes remove the factor of 2 at the cost of more complex analysis.
Contraction Lemma (Ledoux-Talagrand)
Statement
Let be -Lipschitz (i.e., ) with . For any class of real-valued functions:
where .
Intuition
Applying an -Lipschitz function to the outputs of your hypothesis class scales the Rademacher complexity by at most . The lemma is a contraction in the technical sense (the Lipschitz constant cannot create new correlation structure), but the absolute complexity can grow when — for instance, doubles every output. The "shrinkage" picture is only accurate for . The general statement is the linear bound .
Proof Sketch
The proof uses the comparison inequality for Rademacher processes. The key step is showing that for any fixed and Rademacher :
This follows from the contraction principle: since is -Lipschitz and , we have , and the Rademacher average of contracted values is bounded by times the Rademacher average of the original values.
Why It Matters
The contraction lemma lets you bound the Rademacher complexity of the loss class in terms of the Rademacher complexity of the hypothesis class . If the loss is -Lipschitz, then:
The Lipschitz constant depends on the prediction/label range. For the ramp loss, . For squared loss with derivative , the Lipschitz constant is , which gives:
- when (so ), the convention used throughout this page.
- when (so ), the convention used in the worked exercise below.
Pick the convention deliberately and state it. A single written without the bounded range is a recurring source of off-by-2 errors in generalization bounds.
This is practical: you compute the Rademacher complexity of (which is often easier) and multiply by the Lipschitz constant of the loss.
Failure Mode
The contraction lemma requires . If the loss does not satisfy this (e.g., constant offset), you can center it first. Also, the Lipschitz constant can be conservative: if is Lipschitz with constant globally but much smoother in the range actually used, the bound is loose.
Finite-Sample Scalar Contraction (Lean-Verified)
Statement
For a finite sample , a finite nonempty class of scalar-valued functions, and a map satisfying with positive :
The Lean statement is the finite-sample, finite-class empirical Rademacher wrapper around a coordinate-by-coordinate contraction proof.
Intuition
The proof contracts one sample coordinate at a time. At each coordinate, the one-step comparison lemma shows that replacing by cannot increase the sign-average supremum by more than the Lipschitz factor. Iterating over all coordinates gives the finite-sample bound.
Failure Mode
This is deliberately scoped: finite sample, finite nonempty hypothesis class, scalar outputs, empirical Rademacher complexity, and a positive Lipschitz constant. It is not the full general Talagrand contraction principle for infinite classes or stochastic processes.
One-Lipschitz Empirical Rademacher Contraction (Lean-verified)
Statement
For a finite hypothesis index set, finite sample , loss family , and a 1-Lipschitz map :
The Lean theorem is TheoremPath.LearningTheory.RademacherContraction.contraction_empirical.
Intuition
This is the finite-sample, unit-Lipschitz version of the contraction principle. It says that applying a non-expansive scalar transformation to each loss value cannot increase the empirical Rademacher complexity on that sample.
Proof Sketch
The Lean proof first proves the raw sign-sum contraction by replacing one coordinate at a time, then wraps it with the empirical Rademacher definition. The final step factors the nonnegative normalization through the finite supremum and the average over sign vectors.
Failure Mode
This Lean wrapper proves the 1-Lipschitz empirical statement. Scaled -Lipschitz formulations and infinite-index variants are tracked as separate Rademacher extension targets.
High-Probability Rademacher Generalization Gap Bound
Statement
For a finite nonempty hypothesis class with losses bounded by and an iid sample :
where . Combines expected Rademacher symmetrization with the Azuma-style genGap tail bound.
Intuition
The expected Rademacher complexity controls the average generalization gap; the Azuma concentration step turns this into a high-probability bound with an additive slack . The Azuma constant ( in the exponent) is a factor of 4 looser than the sharp McDiarmid form ().
Massart Finite-Class Rademacher Bound (Effective Class)
Statement
For a finite hypothesis class with losses bounded by and a sample of size , the empirical Rademacher complexity is bounded by the number of distinct loss patterns (effective class) on the sample:
where is the number of distinct loss vectors as ranges over the hypothesis class.
Intuition
The empirical Rademacher complexity depends on the hypothesis class only through the distinct loss patterns it produces on the sample. Redundant hypotheses that agree on every sample point contribute nothing. This is the bridge between combinatorial growth functions (Sauer-Shelah, VC dimension) and Rademacher complexity.
Effective-Growth VC-Style Rademacher Bound
Statement
For a hypothesis class whose effective class cardinality on every sample of size is bounded by (the Sauer-Shelah growth function with parameter ), the empirical Rademacher complexity satisfies:
The singleton effective-class case (all hypotheses agree on the sample) is handled by showing .
Intuition
Composing the Sauer-Shelah polynomial bound with the Massart effective-class bound replaces with . The parameter plays the role of the VC dimension. For generic real-valued losses, the user still supplies the effective-growth assumption. For binary classifiers with 0-1 loss, the binary VC bridge is now Lean-verified and derives the effective loss-pattern bound from the binary trace.
Finite-Dimensional Linear Predictor Rademacher Bound (Lean-Verified)
Statement
For a finite nonempty family of Euclidean weights with norm at most and a finite sample with positive , let be the corresponding indexed class of linear predictors.
The Lean file also proves the bounded-input corollary:
Intuition
The Rademacher supremum over norm-bounded linear predictors reduces to the norm of the signed feature sum. Cauchy-Schwarz pulls out the weight radius , and Jensen converts the expected norm into the square root of the sum of squared feature norms.
Failure Mode
This is the finite-dimensional Euclidean, finite-index version. It does not claim an arbitrary Hilbert-space theorem, an infinite weight ball as an unindexed hypothesis class, or a neural-network generalization bound.
Proof Ideas and Templates Used
The Rademacher complexity framework relies on three main techniques:
-
Symmetrization: replace population expectations with empirical expectations using a ghost sample, then introduce Rademacher variables by exploiting the symmetry between the two samples. This is the bridge from generalization gaps to Rademacher complexity.
-
Azuma/McDiarmid-style concentration: used to convert the bound on the expected generalization gap into a high-probability bound. The current Lean proof goes through an exposure martingale and records the resulting denominator explicitly.
-
Contraction: reduce the complexity of the composed loss class to the complexity of the hypothesis class. This modular approach means you only need to compute Rademacher complexity for common function classes (linear functions, kernel classes, etc.) once, and then compose with different losses.
Canonical Examples
Rademacher complexity of linear classifiers
Let and with . Then:
The last step uses and Jensen's inequality.
This gives the bound , which depends on the norms and but not on the ambient dimension . A linear classifier in with and has the same Rademacher complexity as one in . This is how margin-based bounds work: the margin (which constrains and ) controls generalization, not the number of features.
Rademacher complexity of a finite class
If and , then:
This follows from the bound (sub-Gaussian maximal inequality). Setting with gives the result.
Plugging into the generalization bound recovers the finite-class uniform convergence bound from the ERM topic: gap .
Rademacher complexity recovers VC-type bounds
For binary-valued with VC dimension :
This follows from bounding the empirical Rademacher complexity using the growth function: , then applying Sauer-Shelah: . The result is the same order as the VC generalization bound but derived through a different (and more general) route.
Common Confusions
VC dimension is worst-case combinatorial; Rademacher is average-case data-dependent
This is the most important distinction. VC dimension assigns a single number to that is independent of the data distribution. Rademacher complexity depends on the actual sample (or, for , on the distribution ). On data with a large margin, the Rademacher complexity of linear classifiers can be much smaller than what the VC bound predicts, because the data geometry constrains which hypotheses have low empirical risk.
In short: VC dimension asks "how complex is the class in the worst case?" while Rademacher complexity asks "how complex is the class on this data?"
The factor of 2 in the generalization bound is not arbitrary
The bound has , and this factor of 2 comes directly from the symmetrization step. When you introduce the ghost sample and then desymmetrize, you pick up a factor of 2. This is a real structural feature of the proof, not a looseness. For two-sided bounds, you sometimes see ; for one-sided bounds, advanced techniques (localization) can sometimes reduce the constant.
Rademacher complexity is about the function class, not a single function
measures the worst-case correlation over all with random noise. It is not a property of any single function. A single function's correlation with Rademacher noise is , which has mean zero and standard deviation . The Rademacher complexity is the expected supremum of this over the class. It is the maximum, not the typical value.
Summary
- Rademacher complexity measures how well correlates with random noise on sample
- Generalization bound: gap
- The symmetrization lemma connects the generalization gap to Rademacher complexity (factor of 2)
- The contraction lemma: Lipschitz losses preserve Rademacher bounds up to the Lipschitz constant
- Linear classifiers: . depends on norms, not dimension
- Rademacher complexity is data-dependent and often tighter than VC bounds
- For finite classes: (recovers the classical bound)
- For VC-dimension- classes: (recovers the VC bound)
Exercises
Problem
Compute the empirical Rademacher complexity of the class on a sample where each .
Express your answer in terms of and .
Problem
Using the contraction lemma, bound the Rademacher complexity of the class in terms of , assuming and .
Problem
Show that for any class with VC dimension (binary-valued functions), the Rademacher complexity satisfies:
Use Massart's finite lemma: if is a finite set, then .
Related Comparisons
References
Canonical:
- Bartlett & Mendelson, "Rademacher and Gaussian Complexities: Risk Bounds and Structural Results," JMLR 3 (2002), 463-482. jmlr.org. The foundational reference establishing Rademacher complexity as the data-dependent generalization tool.
- Koltchinskii & Panchenko, "Rademacher Processes and Bounding the Risk of Function Learning," High Dimensional Probability II (2000), 443-457. The companion paper introducing Rademacher penalties; also Koltchinskii, "Rademacher Penalties and Structural Risk Minimization," IEEE Trans. Inf. Theory 47(5) (2001), 1902-1914.
- Boucheron, Lugosi, Massart, Concentration Inequalities: A Nonasymptotic Theory of Independence (OUP 2013), Chapter 11. Comprehensive modern treatment of Rademacher averages and symmetrization.
- Shalev-Shwartz & Ben-David, Understanding Machine Learning, Chapter 26
- Mohri, Rostamizadeh, Talwalkar, Foundations of Machine Learning (2018), Chapter 3
Current:
- Wainwright, High-Dimensional Statistics (2019), Chapter 4
- Ledoux & Talagrand, Probability in Banach Spaces (1991), Chapter 4 (contraction principle)
- Koltchinskii, "Local Rademacher Complexities and Oracle Inequalities in Risk Minimization," Annals of Statistics 34(6) (2006), 2593-2656. The localization refinement that tightens the factor-of-2 from basic symmetrization.
Next Topics
From Rademacher complexity, the next step is:
- Algorithmic stability: generalization bounds that depend on the algorithm (not just the hypothesis class), which can explain generalization in regimes where complexity-based bounds fail
Last reviewed: April 22, 2026
Canonical graph
Required before and derived from this topic
These links come from prerequisite edges in the curriculum graph. Editorial suggestions are shown here only when the target page also cites this page as a prerequisite.
Required prerequisites
9- Concentration Inequalitieslayer 1 · tier 1
- Understanding Machine Learning (Shalev-Shwartz, Ben-David)layer 1 · tier 1
- Empirical Risk Minimizationlayer 2 · tier 1
- Hypothesis Classes and Function Spaceslayer 2 · tier 1
- Sub-Gaussian Random Variableslayer 2 · tier 1
Derived topics
7- Algorithmic Stabilitylayer 3 · tier 1
- PAC-Bayes Boundslayer 3 · tier 1
- Symmetrization Inequalitylayer 3 · tier 1
- Implicit Bias and Modern Generalizationlayer 4 · tier 1
- Contraction Inequalitylayer 3 · tier 2
+2 more on the derived-topics page.