Foundations
Continuity in Rⁿ
Epsilon-delta continuity, uniform continuity, and Lipschitz continuity in Euclidean space. Lipschitz constants control how fast function values change and appear throughout optimization and generalization theory.
Prerequisites
Why This Matters
Continuity is the minimal regularity condition you usually want on a loss function: without it, small changes in parameters need not produce small changes in predictions, and the extreme value theorem — which guarantees a minimizer on a nonempty compact set — does not apply. Continuity does not, by itself, make gradient methods well-behaved: gradient descent additionally needs differentiability or subgradient structure, smoothness or step-size control, some convexity / stationarity assumption, lower boundedness, and frequently coercivity or compactness of sublevel sets. So treat continuity as the entry-level regularity that makes existence-of-minimizers arguments possible, not as a sufficient condition for any particular optimizer to converge.
Hide overviewShow overview
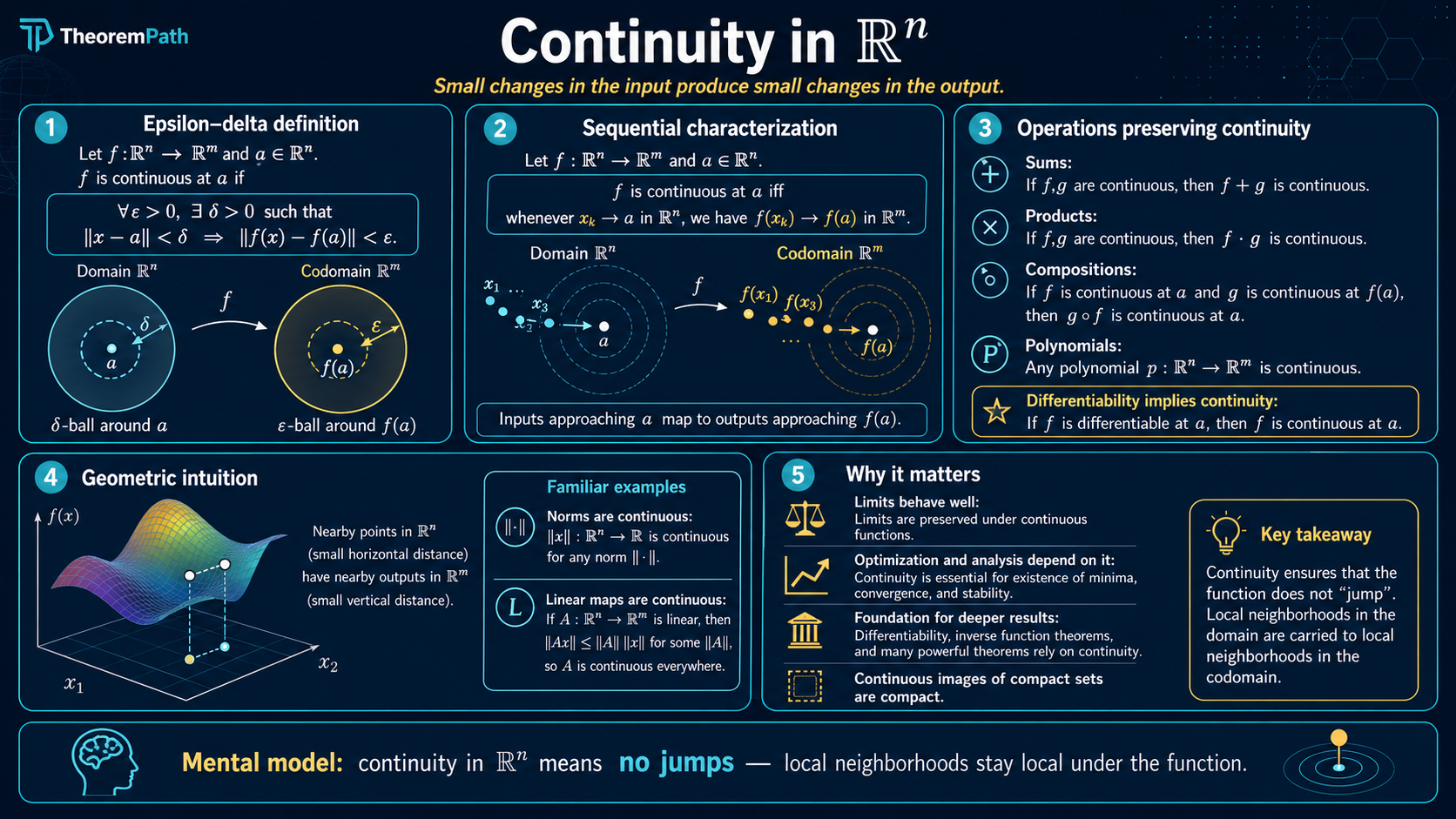
is the variant that appears most in ML theory. Generalization bounds for neural networks often depend on the Lipschitz constant of the network. Wasserstein GANs enforce a Lipschitz constraint explicitly.
The greek letters and are the canonical pair in every continuity definition below.
Core Definitions
Continuity at a Point
A function (where carries the standard metric) is continuous at if and only if for every , there exists such that:
The choice of can depend on both and the point .
Uniform Continuity
is uniformly continuous on a set if and only if for every , there exists such that for all :
The depends only on , not on the specific points .
Lipschitz Continuity
is -Lipschitz on a set if and only if there exists such that for all :
The smallest such is the Lipschitz constant of on .
The hierarchy is strict: Lipschitz implies uniformly continuous implies continuous. The converses fail. The function on is uniformly continuous but not Lipschitz (its derivative blows up at 0). The function on is continuous but not uniformly continuous.
Composition and Algebraic Properties
Continuous functions compose: if is continuous at and is continuous at , then is continuous at . Sums, products, and quotients (where the denominator is nonzero) of continuous functions are continuous.
For Lipschitz functions, the composition rule is quantitative. If is -Lipschitz and is -Lipschitz, then is -Lipschitz. This multiplicative blowup is why deep networks can have large Lipschitz constants: each layer multiplies.
Main Theorems
Extreme Value Theorem
Statement
If is continuous and is compact and nonempty, then attains its maximum and minimum on . That is, there exist such that:
Intuition
A continuous function on a closed and bounded set cannot "escape to infinity" or "approach but never reach" its supremum. Compactness traps sequences and continuity preserves limits.
Proof Sketch
Since is continuous and is compact, is compact in (continuous image of a compact set is compact). A compact subset of is closed and bounded, so it contains its supremum and infimum.
Why It Matters
This theorem guarantees that optimization problems over compact sets have solutions. When you minimize a continuous loss over a bounded parameter space, a minimizer exists. Without compactness, minimizers may not exist: but no achieves it.
Failure Mode
Fails without compactness. On the open interval , the function is continuous but has no maximum. Fails without continuity: the indicator function on achieves its max but a discontinuous function in general need not.
Heine-Cantor Theorem
Statement
If is continuous and is compact, then is uniformly continuous on .
Intuition
On a compact set, continuity cannot degrade from point to point. The worst-case over all points in is still positive because has no "escape to infinity" where the modulus of continuity might shrink to zero.
Proof Sketch
Suppose is not uniformly continuous. Then there exists and sequences with but . By compactness, extract a convergent subsequence . Then as well. By continuity at , , contradicting .
Why It Matters
This is why bounded parameter spaces simplify analysis. A continuous loss function on a compact parameter set is automatically uniformly continuous, which makes approximation arguments (like discretizing the parameter space) valid.
Failure Mode
Fails on non-compact domains. is continuous on but not uniformly continuous: for large , a small change in produces a large change in .
Examples
Why $\sqrt{x}$ is uniformly continuous on $[0,1]$ but not Lipschitz
On , is continuous and the domain is compact, so by Heine-Cantor it is uniformly continuous. To see it is not Lipschitz, note blows up as . Take and : but , so the ratio grows without bound. No single works.
The modulus of continuity is . This is a Hölder continuity of exponent , a strictly weaker condition than Lipschitz (Hölder with exponent 1).
Lipschitz constant of a linear layer
Let with . For any , , where is the operator norm (largest singular value). The Lipschitz constant of an affine map is exactly its operator norm; the constant contributes nothing because it cancels in the difference.
For a deep network with each a linear layer followed by a 1-Lipschitz activation (ReLU, tanh, sigmoid all have Lipschitz constant 1), the composition rule gives . Spectral normalization enforces to keep the end-to-end Lipschitz constant bounded; this is the mechanism behind Wasserstein GAN training.
Why Lipschitz Constants Matter in ML
Three places where the Lipschitz constant directly controls a quantity of interest:
- Gradient descent step size. For an -smooth function (gradient is -Lipschitz), gradient descent with step size is monotone non-increasing in the loss. Step sizes above can diverge even on convex problems. See SGD convergence.
- Generalization bounds. Many uniform-convergence bounds for neural networks scale with the product of layer-wise Lipschitz constants (operator norms of weight matrices). This connects directly to the Rademacher complexity of the function class: smaller Lipschitz constants give tighter generalization bounds.
- Robustness. A network with Lipschitz constant has the property that an input perturbation of size changes the output by at most . Adversarial examples exploit large local Lipschitz constants; certified robustness methods enforce small ones explicitly.
The price of small Lipschitz constants is expressiveness. Universal approximation requires unbounded Lipschitz constants in general; trading off the Lipschitz constant against approximation error is one of the central design tensions in modern deep learning theory.
Common Confusions
Lipschitz constant depends on the norm
The Lipschitz constant of a function depends on which norm you use. A function that is 1-Lipschitz in the norm may have a different Lipschitz constant in the norm. In ML, the norm is the default unless stated otherwise.
Differentiable does not imply Lipschitz
A function can be differentiable everywhere without being Lipschitz. on is smooth but not Lipschitz because its derivative is unbounded.
The right "bounded derivative gives Lipschitz" statement also depends on the codomain and the domain geometry:
- Scalar-valued on a convex domain. If for all , then is -Lipschitz (mean value theorem along line segments).
- Vector-valued on a convex domain. The relevant object is the operator norm of the Jacobian: if for all , then is -Lipschitz. Bounding individual partials is not enough; you need the operator-norm bound.
- Non-convex domain. Both statements can fail: even with a bounded gradient, a "U"-shaped domain can force a long path between two nearby points and make the global Lipschitz constant much larger than the local gradient bound.
Exercises
Problem
Prove that is 1-Lipschitz on .
Problem
Let be differentiable with for all . Prove that is -Lipschitz.
References
Canonical:
- Rudin, Principles of Mathematical Analysis (1976), Chapters 4 and 7
- Apostol, Mathematical Analysis (1974), Chapter 4
- Folland, Real Analysis (1999), Chapter 4 (continuity and topology)
Current:
- Shalev-Shwartz & Ben-David, Understanding Machine Learning (2014), Section 26.1 (Lipschitz conditions in generalization)
- Vershynin, High-Dimensional Probability (2018), Section 5.2.2 (Lipschitz functions and concentration)
- Deisenroth, Faisal, Ong, Mathematics for Machine Learning (2020), Section 5.1 (continuity in the context of differentiation)
- Arjovsky, Chintala, Bottou, "Wasserstein GAN" (2017), arXiv:1701.07875 (Lipschitz constraint enforced on the critic)
- Miyato et al., "Spectral Normalization for Generative Adversarial Networks" (2018), arXiv:1802.05957 (constraining per-layer Lipschitz constants via spectral norm)
- Virmaux & Scaman, "Lipschitz Regularity of Deep Neural Networks" (2018), NeurIPS (bounding end-to-end Lipschitz constants of deep networks)
Last reviewed: April 26, 2026
Canonical graph
Required before and derived from this topic
These links come from prerequisite edges in the curriculum graph. Editorial suggestions are shown here only when the target page also cites this page as a prerequisite.
Required prerequisites
1- Metric Spaces, Convergence, and Completenesslayer 0A · tier 1
Derived topics
4- Differentiation in Rⁿlayer 0A · tier 1
- Taylor Expansionlayer 0A · tier 1
- Classical ODEs: Existence, Stability, and Numerical Methodslayer 1 · tier 1
- Convex Optimization Basicslayer 1 · tier 1