AI Safety
Reward Models and Verifiers
How preference reward models, outcome verifiers, process reward models, executable checks, and ensembles provide different training signals, and where Goodhart pressure enters.
Prerequisites
Why This Matters
Hide overviewShow overview
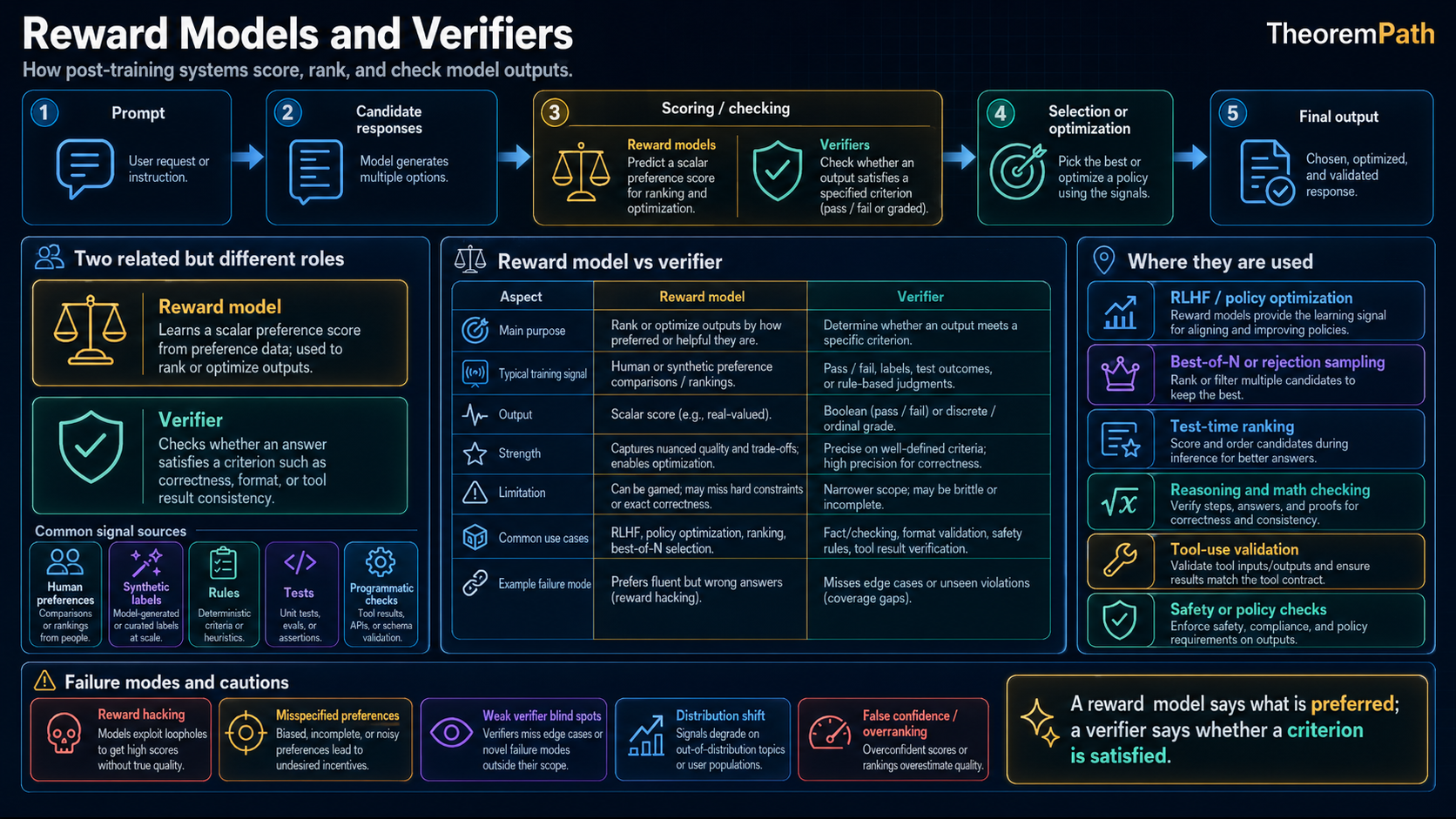
Every serious post-training pipeline needs a training or selection signal: something that tells the model which outputs are good and which are bad. This signal often comes from either a reward model (a learned function that predicts human preferences) or a verifier (a system that checks output correctness).
The distinction matters because the two signals fail in different ways. Reward models are flexible, but they can be hacked, drift under distribution shift, and learn biases from their training data. Verifiers are narrower, and on domains with checkable answers they can be more stable than a learned scalar preference model. When a verifier says an answer passes, it passes that check, but the check can still be incomplete: partial test coverage, incorrect specifications, or tamperable evaluation environments can all break the guarantee.
Understanding this distinction explains why open-ended assistant behavior still leans on preference signals, while math, code, and formal tasks increasingly use verifiable rewards or verifier-guided selection where the target property is actually checkable.
Mental Model
Think of two ways to evaluate a student's essay:
- Reward model approach: Ask a panel of judges to rate it. The judges are imperfect. They can be swayed by confident prose, they disagree with each other, and a clever student can learn to write essays that score well without actually being good.
- Verifier approach: Check each factual claim against a reference. The checker is narrow (it can only verify facts, not evaluate style) but reliable within its scope: a claim is either supported by the reference or not.
Reward models are like judges: flexible, subjective, hackable. Verifiers are like fact-checkers: narrower, more objective, and robust only within the scope of the check.
Training Signal Ledger
Reward models, verifiers, and PRMs are not interchangeable. The right question is what the signal measures, where it is dense, and how it fails under optimization pressure.
signal, coverage, failure mode
Signal
Preference reward model
- Source
- Pairwise human or AI preferences
- Typical Use
- Ranks open-ended responses for RLHF, DPO-style data curation, or best-of-N selection.
- Why It Helps
- Broad coverage: helpfulness, tone, style, refusal quality.
- Audit Risk
- Proxy reward can be overoptimized; surface features can masquerade as quality.
Signal
Outcome verifier
- Source
- Final-answer check, unit tests, proof checker, known answer
- Typical Use
- Filters or rewards complete candidates after a rollout.
- Why It Helps
- Clear pass/fail signal when the task is genuinely checkable.
- Audit Risk
- Sparse feedback; test coverage and specifications can be incomplete or gameable.
Signal
Process reward model
- Source
- Step-level labels or rollout-derived step values
- Typical Use
- Guides search over partial reasoning chains and supplies denser RL feedback.
- Why It Helps
- Earlier feedback than an outcome-only signal.
- Audit Risk
- Still a learned model; step errors can compound across a long chain.
Signal
Conservative ensemble
- Source
- Multiple reward models with independent seeds or splits
- Typical Use
- Penalizes candidates where reward models disagree or only one model is excited.
- Why It Helps
- Reduces some overoptimization pressure in synthetic preference studies.
- Audit Risk
- Shared data and architecture create shared blind spots; it is mitigation, not proof.
Before Trusting The Curve
- What property is actually checked?
- How much of the task distribution is covered?
- Can the model see, infer, or modify the evaluator?
- Is the signal used for training, selection, or reporting only?
Reward Models
The Bradley-Terry Framework
Bradley-Terry Reward Model Training
Statement
Given a dataset of human preference comparisons , a reward model is trained by maximizing:
Under the Bradley-Terry model, the probability of preferring over is:
The reward model learns a scalar scoring function such that preferred outputs receive higher scores than dispreferred ones.
Intuition
The reward model converts ordinal preferences (A is better than B) into cardinal scores (A scores 3.2, B scores 1.7). The sigmoid function maps the score difference to a preference probability. The loss encourages the model to assign scores that are consistent with observed human preferences.
Why It Matters
The reward model is the bridge between human judgment and machine optimization. In RLHF, the policy is optimized to maximize the reward model's score. In best-of-N sampling, the reward model selects the best candidate. The quality of the entire post-training pipeline depends on the quality of this single learned function.
Failure Mode
The Bradley-Terry model assumes preferences are generated by a single latent scalar reward via . The pairwise comparisons are stochastic, but the induced expected preference ordering on outputs is total and transitive. In reality, human preferences are often intransitive (A > B, B > C, but C > A), context-dependent, and influenced by factors irrelevant to quality (length, confidence, formatting). A scalar reward cannot represent intransitive preferences at all, and the fitted reward model absorbs the rest of these imperfections and presents them as a clean scalar score, creating a false sense of precision.
Why Reward Models Are Fragile
Problem 1: Distributional shift. The reward model is trained on outputs from . As the policy changes during RL, it generates outputs increasingly different from the training distribution. The reward model's scores can become unreliable on these out-of-distribution outputs. This is not a hypothetical concern; it is one common route to reward overoptimization.
Problem 2: Reward features. Reward models learn spurious correlations between surface features and human preferences. Common examples:
- Longer responses tend to be rated higher the model learns "length = quality"
- Confident language is preferred the model learns "confidence = quality"
- Markdown formatting looks professional the model learns "formatting = quality"
A model optimized against these spurious features produces long, confident, well-formatted responses that may be substantively wrong.
Problem 3: Goodhart's Law.
Reward Model Overoptimization
Statement
Let be the true (unobservable) reward and the learned proxy reward. Assume the policy is the KL-constrained optimum of at inverse KL weight , and that the two expected rewards are differentiable in (these are the regularity conditions under which the sign claims below hold. For approximate RL trajectories such as a fixed number of PPO steps, the signed statements become empirical tendencies rather than theorems). Then as the policy is optimized more aggressively against (by decreasing ), the proxy reward increases monotonically, while the true reward typically first increases and then decreases:
The first inequality is the envelope property of the KL-constrained optimum and requires the monotone-optimum assumption above. The second is the empirical overoptimization curve fit by Gao et al. 2023. The point where true reward peaks is the optimal level of optimization. Beyond it, further optimization actively makes the model worse according to the quantity we actually care about.
Intuition
Imagine optimizing a student's exam score. Initially, studying improves both the score and the knowledge. But eventually, the student discovers tricks that improve the score without improving knowledge (e.g., writing longer answers, using jargon). The score keeps going up while the actual knowledge plateaus and then declines (because time spent on tricks displaces time spent learning).
Why It Matters
This result is documented by Gao, Schulman, and Hilton (2023) as an empirical scaling law. Their functional forms are for best-of- and for RL fine-tuning, where is the square-root KL to the base policy. These are empirical fits to synthetic-preference experiments, not derived laws. It is a simplification of the true optimization dynamics but captures the Goodhart gap pattern: gold reward initially rises with optimization pressure, then falls as the policy over-exploits the reward model. The practical implication: monitor true quality (via human evaluation) during RL training and stop before overoptimization kicks in.
Failure Mode
The overoptimization point depends on the quality of the reward model, and you cannot determine it without access to the true reward (which is why you are using a proxy in the first place). In practice, teams use held-out human evaluations at checkpoints, but this is expensive and discrete. Between checkpoints, the model can overshoot into the overoptimized regime.
Reward Model Ensembling
One partial mitigation for overoptimization is to train an ensemble of reward models with different seeds or data splits and aggregate their scores (mean, min, or conservative quantile). Coste et al. (2023) show that ensemble aggregation reduces the Goodhart gap in synthetic-preference experiments: optimizing against a worst-case or mean-over-ensemble reward slows the decay of the true reward as KL grows. Eisenstein et al. (2023) confirm the effect but document its limit. Ensembles mitigate reward hacking but do not eliminate it, because the ensemble members share training data, inductive biases, and blind spots, so they agree on many of the same spurious features. Ensembling is a useful tool and not a fix for the underlying proxy-reward problem.
Verifiers
Verifiers check outputs against objective criteria rather than predicting human preferences. They do not rate. They verify.
The clean distinction: verifiers (math, code) evaluate against ground truth (unit tests, a formal proof, a known numerical answer). Reward models learn from preferences, with no ground-truth signal beyond the preference label. Process reward models are a hybrid: they evaluate intermediate reasoning steps, but the step labels are themselves learned (from humans or from Monte Carlo rollout success), so a PRM inherits the fragility of a reward model while aiming at the density of a verifier. Verifier-guided test-time search exploits this density without requiring a PRM to be globally calibrated.
Types of Verifiers
- Code execution: Run the generated code against test cases. Pass or fail.
- Math verification: Check the final numerical answer or use a formal proof assistant (Lean, Isabelle) to verify a proof.
- Fact-checking: Compare generated claims against a knowledge base or retrieve supporting/contradicting evidence.
- Constraint checking: Verify that the output satisfies specified format or content constraints.
Why Verifiers Are More Robust
Verifiers check the output, not the process. A reward model says "this looks like a good response." A verifier says "this response is factually correct" or "this code passes all tests." The critical difference:
- Reward models can be hacked by outputs that look good but are wrong
- Verifiers are harder to reward-hack than scalar reward models because they check a property of the output rather than predict preference, but they are not immune. Unit-test verifiers can be gamed by memorizing tests or by tampering with the evaluation procedure (Denison et al. 2024), formal proof verifiers still trust the axioms and specification, and PRM step-scores can themselves be Goodharted. On math benchmarks they resist the most common failure modes, but overoptimization still occurs (Gao et al. 2023, Skalse et al. 2022)
- Reward models degrade under distributional shift; verifiers are more stable across distributions within their checkable domain, but their signal is only as sound as the specification they check against
The limitation: verifiers only exist for domains with checkable answers. You cannot build a verifier for "is this essay insightful?" or "is this response helpful?" These subjective qualities require reward models.
Process Reward Models vs Outcome Reward Models
Process vs Outcome Reward Model Tradeoff
Statement
An outcome reward model (ORM) scores only the final answer: . A process reward model (PRM) scores each intermediate step: .
The tradeoff:
- ORM: When the outcome is checked by an exact verifier (math equality, unit tests, formal proof), the reward is unbiased: the final answer is either correct or not. When the ORM is a learned classifier of final-answer quality, it inherits the usual learned-model biases. Either way the signal is sparse — it appears only at the end of a long reasoning chain — and the variance of credit assignment grows with chain length.
- PRM: Dense signal (feedback at each step) but biased even when the outcome verifier is exact: the PRM is a learned model that can be wrong about intermediate steps. Bias comes from PRM training errors.
For a chain of steps with per-step PRM error : the total PRM bias scales as , while ORM variance scales as where is the number of rollouts.
Intuition
Judging a long math derivation by only looking at the final answer (ORM) is like grading an exam by only checking the last line. You miss where the student went wrong, and you cannot help them improve their reasoning process. Judging each step (PRM) is like grading each line. You get rich feedback, but you need a grader who understands the subject well enough to evaluate each step. If the per-step grader is unreliable, the accumulated errors can mislead.
Why It Matters
The PRM vs ORM choice determines the granularity of the training signal for reasoning models. PRMs enable step-level search (beam search over reasoning steps) and provide dense rewards for RL training. ORMs are simpler and less dependent on step labels, but they require many rollouts to reduce variance. Recent systems often combine dense process-style signals with outcome checks, using one signal to guide search and another to verify a final answer.
PRM Training
PRMs require step-level labels: for each reasoning step, "was this step correct?" These labels are expensive to collect from humans. An alternative: automated PRM training via Monte Carlo estimation. For each step in a reasoning chain:
- Run many rollouts from that step to completion
- Check how many rollouts reach the correct final answer
- Label the step as "correct" if the success rate is above a threshold
This provides noisy but scalable step-level labels without human annotators.
Public technical reports and open recipes increasingly separate subjective preference signals from verifiable task rewards. DeepSeek-R1 reports RL on verifiable tasks such as math, coding competitions, and STEM problems. Tulu 3 describes a post-training recipe with SFT, DPO, and reinforcement learning with verifiable rewards. The practical pattern is not "verifiers everywhere"; it is reward models for open-ended quality, verifiers where correctness is checkable, and explicit evaluation for the boundary cases between them.
The Signal Tension
Reward models and verifiers represent two ends of a spectrum:
| Property | Reward Model | Verifier |
|---|---|---|
| Signal | Dense (scalar for any output) | Sparse (binary for checkable outputs) |
| Coverage | Universal (any domain) | Narrow (only verifiable domains) |
| Robustness | Fragile (hackable, drifts) | More stable within the checked specification |
| Bias | High (encodes human biases) | Lower when the specification is correct |
| Scalability | Limited by preference data | Limited by verifier domains |
A practical research direction is extending reliable checks to more domains while making learned preference models harder to overoptimize. Fact-checking, consistency checking, conservative reward-model ensembles, iterated data collection, and explicit tamper-resistance all live in this middle zone.
Common Confusions
A high reward model score does not mean high quality
The reward model score is a proxy for quality, trained on a finite sample of human preferences. A score of 4.2 vs 3.8 does not mean one response is objectively better. It means the reward model predicts the first would be preferred by the kind of human raters who produced the training data. This prediction may be wrong, especially for outputs far from the training distribution.
Verifiers are not reward models with better data
Reward models and verifiers are structurally different computational objects. A reward model is a learned function that maps outputs to scalar scores. A verifier is a procedure that checks a property of the output (runs code, checks a proof, queries a database). Improving a reward model's training data does not make it a verifier. The distinction is between predicting quality and checking correctness.
Process reward models are not verifiers
A PRM is still a learned model that can be wrong. It predicts whether a reasoning step is correct. It does not prove it. PRMs can be hacked just like any other reward model. They are better than ORMs for guiding search because they provide earlier signal, but they are not a substitute for ground-truth verification.
Summary
- Reward models: trained on Bradley-Terry preferences, flexible but hackable
- Verifiers: check correctness objectively, robust but narrow in domain
- Goodhart's law: optimizing a proxy reward past a certain point makes the model worse
- Overoptimization: proxy reward increases monotonically, true reward peaks then declines
- PRM: dense step-level signal, potentially biased. ORM: sparse final signal, unbiased
- Reward models encode human biases (length preference, confidence preference)
- Verifiers work for code (tests), math (proofs), facts (retrieval). Not for style
- Strong systems often combine reward models for general quality with verifiers for checkable correctness
Exercises
Problem
A reward model assigns scores and to two responses. Under the Bradley-Terry model, what is the predicted probability that a human rater prefers over ?
Problem
The Gao et al. (2023) best-of- scaling law for reward model overoptimization fits the form:
where is the square-root KL to the reference policy, relates to reward model quality, and relates to reward model error. Find the optimal that maximizes , and show that increases with reward model quality .
Problem
Design a hybrid system that uses both a reward model and a verifier for training a code generation model. Specify: (a) when each signal is used, (b) how they are combined, and (c) what failure modes the hybrid avoids that neither component alone can handle.
References
Pre-canonical:
- Bradley and Terry, "Rank Analysis of Incomplete Block Designs: I. The Method of Paired Comparisons", Biometrika 39(3/4):324-345 (1952). The statistical model behind pairwise preference fitting.
- Amodei et al., "Concrete Problems in AI Safety" (2016). Framed reward hacking, negative side effects, and scalable oversight as first-class problems before RLHF made them operational.
Canonical:
- Christiano et al., "Deep Reinforcement Learning from Human Preferences" (2017). Bradley-Terry reward model framework from pairwise preferences.
- Stiennon et al., "Learning to Summarize from Human Feedback" (2020). The summarization RLHF pipeline that directly seeded InstructGPT.
- Ouyang et al., "Training Language Models to Follow Instructions with Human Feedback" (InstructGPT, 2022). Reward modeling and PPO for instruction-tuned LLMs.
- Bai et al., "Training a Helpful and Harmless Assistant with RLHF" (Anthropic HH, 2022). Preference data collection at scale.
- Cobbe et al., "Training Verifiers to Solve Math Word Problems" (2021). Outcome verifiers on GSM8K.
- Casper et al., "Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback" (2023). Survey of reward-model, preference-data, and policy-optimization limitations.
Current:
- Gao, Schulman, and Hilton, "Scaling Laws for Reward Model Overoptimization" (2023). Empirical (best-of-) and (RL) fits for the Goodhart gap, where .
- Lightman et al., "Let's Verify Step by Step" (2023). Process reward models on PRM800K.
- Wang et al., "Math-Shepherd: Verify and Reinforce LLMs Step-by-step without Human Annotations" (2024). Automated PRM training via Monte Carlo rollouts.
- Coste et al., "Reward Model Ensembles Help Mitigate Overoptimization" (2023/2024). Ensemble aggregation reduces the Goodhart gap in synthetic preference setups.
- Eisenstein et al., "Helping or Herding? Reward Model Ensembles Mitigate but Do Not Eliminate Reward Hacking" (2023). Ensembles are a partial fix, not a solution.
- Skalse et al., "Defining and Characterizing Reward Hacking" (2022). Formal definition of reward hacking.
- Denison et al., "Sycophancy to Subterfuge: Investigating Reward-Tampering in Language Models" (2024). Reward-tampering and specification-gaming risks in language-model environments.
Next Topics
The natural next steps from reward models and verifiers:
- Test-time compute and search: using verifiers at inference time
- DPO vs GRPO vs RL reasoning: how reward/verifier signals drive different training methods
Last reviewed: April 26, 2026
Canonical graph
Required before and derived from this topic
These links come from prerequisite edges in the curriculum graph. Editorial suggestions are shown here only when the target page also cites this page as a prerequisite.
Required prerequisites
4- RLHF and Alignmentlayer 4 · tier 2
- Post-Training Overviewlayer 5 · tier 2
- Reasoning Data Curationlayer 5 · tier 2
- Test-Time Compute and Searchlayer 5 · tier 2
Derived topics
3- DPO vs GRPO vs RL for Reasoninglayer 5 · tier 2
- Reward Hackinglayer 5 · tier 2
- Verifier Design and Process Rewardlayer 5 · tier 2
Graph-backed continuations