LLM Construction
Test-Time Compute and Search
Spending more inference compute through best-of-N, verifier-guided search, tree search, process rewards, and latent/internal computation, with gains limited by verifier quality and base pass rate.
Prerequisites
Why This Matters
Hide overviewShow overview
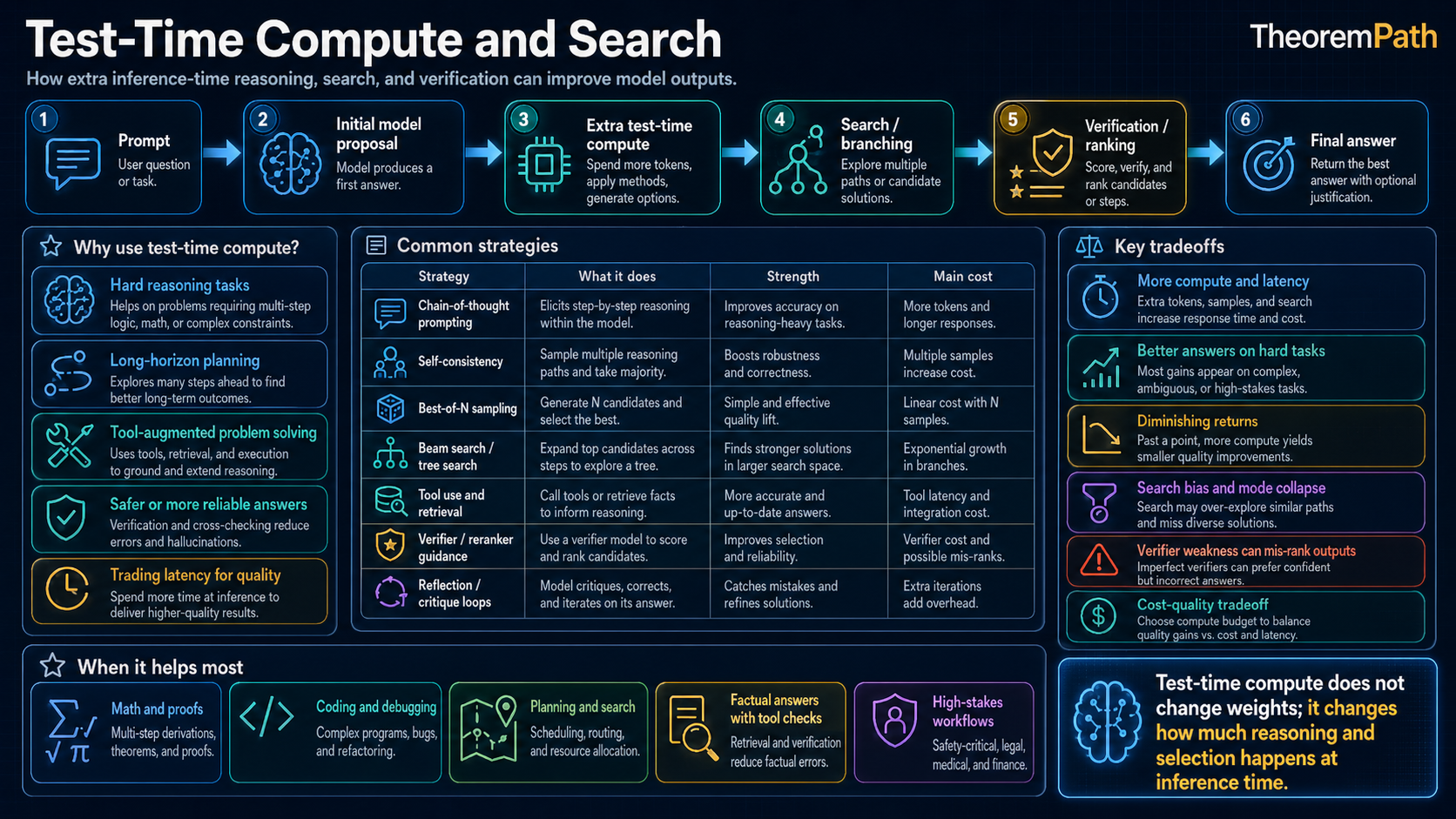
Training scaling laws describe how pretraining compute, data, and parameters affect loss. Test-time compute is a different choice: spend more work on a single query by sampling more candidates, searching over partial reasoning traces, calling verifiers, or allocating extra internal computation before the final answer.
The useful claim is narrower than "more compute means better reasoning." Extra inference compute pays off when three conditions hold together: the model has a nonzero base pass rate on the task, the candidate set adds real diversity rather than echoing the same failure mode, and the selection signal correlates with true success. Drop any one and longer outputs just become longer mistakes.
Mental Model
A model that commits to a single answer in one forward pass spends a fixed compute budget. A model that is uncertain can convert additional inference compute into accuracy through four mechanisms:
- Best-of-: generate candidates, select via verifier or majority vote
- Process reward: produce step-level reasoning scored by a process reward model
- Tree search: expand and backtrack through partial solutions
- Latent reasoning: iterate internally before emitting tokens (see latent reasoning)
Each trades inference cost for accuracy. The empirical questions are how much accuracy improves with budget, where the curve flattens, and how the answer depends on verifier quality.
Inference Compute: The Core Idea
Test-Time Compute
Test-time compute (or inference compute) is the total computation spent generating a response to a single query. For a standard autoregressive model generating tokens with parameters, inference compute is approximately FLOPs. Test-time compute scaling increases this by generating multiple candidates, performing search, or extending the reasoning chain.
The standard approach generates one response: compute . Test-time scaling methods spend a larger multiple of this cost to produce, search, or evaluate candidate answers. The central question is not just whether quality improves, but whether the improvement survives the cost, latency, verifier, and benchmark assumptions.
Best-of-N Sampling
The simplest test-time scaling method: generate independent responses and select the best one using a verifier or reward model.
Best-of-N Scaling with a Perfect Verifier
Statement
If the model produces a correct answer with probability per sample, and the verifier perfectly identifies correctness, then the probability of at least one correct answer among samples is:
For small , this scales approximately linearly: when . To achieve success probability , you need:
samples. The cost scales as to achieve high confidence.
Intuition
If the model has even a small chance of producing the correct answer, generating enough samples makes success near-certain. The verifier acts as a filter: it cannot make the model smarter, but it can select the model's best work from many attempts. The bottleneck shifts from generation quality to verifier quality.
Why It Matters
Best-of-N is a simple baseline for test-time compute scaling. It requires no additional training, only a good verifier. For math and code, where verifiers are reliable (run the code, check the proof), best-of-N gives substantial improvements. For open-ended text where verification is hard, the gains are smaller.
Failure Mode
When the verifier is imperfect (a reward model rather than a ground-truth checker), best-of-N suffers from reward hacking at inference time. The selected sample maximizes the verifier's score, not actual quality. As increases, the selected sample increasingly exploits verifier weaknesses. This is the inference-time analog of reward model overoptimization.
Selection Without an External Verifier
Best-of-N assumes you can score candidates from outside. When no verifier exists, two cheap selection rules remain:
- Self-consistency / majority voting (Wang et al., 2022). Sample chains of thought, extract the final answer from each, and return the most common. Works on tasks with a small discrete answer space (math word problems, multiple choice). Equivalent to a verifier that votes for whatever the model most often agrees with itself on. Fails on open-ended outputs and when the model is consistently wrong in the same way.
- Self-evaluation. Ask the model to score its own candidates. Cheap, but gives a verifier-like signal whose quality is bounded by the model's own judgment. Useful as a baseline; weaker than a trained reward model on hard reasoning.
Self-consistency is strictly weaker than a good verifier: it cannot detect a shared mistake. But on benchmarks where the answer space is small and the model's wrong answers are diverse (so the right one wins the vote), the gap between self-consistency and a perfect verifier is small.
Verifier-Guided Search
Best-of-N generates complete responses independently. More sophisticated methods use the verifier to guide generation during the reasoning process.
Process Reward Models (PRMs) vs Outcome Reward Models (ORMs)
- ORM: Scores the final answer. Binary: correct or not.
- PRM: Scores each intermediate reasoning step. Guides the search by pruning bad reasoning paths early.
With a PRM, you can perform step-level beam search: at each reasoning step, generate multiple continuations, score them with the PRM, and keep only the top-. This avoids wasting compute on reasoning paths that go wrong early.
Monte Carlo Tree Search (MCTS) for Reasoning
MCTS treats reasoning as a sequential decision problem:
- State: The reasoning chain so far
- Action: The next reasoning step
- Reward: Correctness of the final answer (or PRM score)
- Rollout: Complete the reasoning chain from the current state
The standard MCTS loop:
- Select a promising node using UCB (upper confidence bound)
- Expand by generating a new reasoning step
- Simulate by completing the chain (or using a value estimate)
- Backpropagate the outcome to update node statistics
This is the reason game-search language appears in some reasoning papers. The reasoning trace becomes the "game tree," and each step becomes a "move."
Method Matrix
| Method | Where the extra compute goes | Selection signal | Strongest use cases | Main failure mode |
|---|---|---|---|---|
| Single pass | one rollout | none | easy tasks, low latency | first answer is brittle |
| Best-of-N | many complete candidates | final-answer verifier or ORM | code, math, constrained generation | reward overoptimization or duplicated wrong answers |
| Self-consistency / majority vote | many complete candidates | most common final answer | discrete-answer reasoning when no verifier exists | shared failure mode across samples sweeps the vote |
| PRM-guided beam/tree search | branch expansion on partial traces | process reward model | long multi-step reasoning with meaningful step scores | PRM label noise and branch collapse |
| MCTS / verifier-guided search | targeted rollouts on promising prefixes | rollout reward, PRM, or verifier | theorem proving, program synthesis, hard math | expensive search with mismatch between search policy and final verifier |
| Latent or silent compute | extra internal steps per answer | trained controller or reasoning objective | tasks where extra internal depth helps more than extra text | opaque computation and weak audit surface |
These methods can be combined. A modern reasoning system may use long chain-of-thought rollouts, a verifier for best-of-N selection, and a PRM to prune branches during search.
Chain-of-Thought as Inference Compute
Chain-of-Thought Scaling
Chain-of-thought (CoT) prompting increases inference compute by generating intermediate reasoning tokens before the final answer. A model generating reasoning tokens plus answer tokens spends approximately FLOPs. More reasoning tokens means more compute.
The hypothesis: the transformer's fixed per-token computation is insufficient for hard reasoning, and generating intermediate tokens provides additional "serial computation" that enables multi-step inference.
When Test-Time Scaling Helps
Statement
For verifiable reasoning tasks, extra test-time compute can improve selected accuracy when it creates useful candidate diversity and the selection signal is better than chance.
There is no universal law of the form
that applies across models, benchmarks, search methods, and verifiers. Empirical curves are method- and task-dependent: they may improve quickly, improve slowly, or saturate once the model's candidate distribution stops producing useful new solutions.
Intuition
More inference compute is useful when it changes the set of candidate solutions and the system can identify the better ones. If every candidate repeats the same wrong pattern, or if the verifier prefers polished wrong answers, more compute does not buy reliability.
Why It Matters
This is the honest version of inference scaling. Training compute and inference compute can be partially substitutable on some reasoning benchmarks, but the tradeoff is conditional. A smaller model plus search can outperform a larger single-pass model when the smaller model already has a useful pass rate and the search procedure is compute-aware.
Failure Mode
Verifier overoptimization is the main failure mode. As the number of candidates increases, an imperfect reward model is more likely to select responses that exploit its blind spots. The selected answer can look better to the verifier while getting worse by the true task metric.
Latent Reasoning
One active direction is reasoning in hidden states rather than in visible tokens.
Standard chain-of-thought reasoning forces the model to express all reasoning as text tokens. This has limitations:
- Bandwidth: Natural language is a low-bandwidth communication channel for complex reasoning
- Faithfulness: The written chain-of-thought may not reflect the model's actual computation
- Efficiency: Generating tokens is expensive; internal computation is cheaper
Latent reasoning models use special "thinking tokens" that are processed by the transformer but not decoded into text. The model can perform many steps of internal computation (many forward passes through "thinking" positions) before producing an output token. This increases the model's effective depth for hard problems.
This is an active research area. The theoretical framework is developing: latent reasoning can be viewed as giving the model a variable-depth computation graph rather than the fixed depth of a standard transformer.
For reasoning tasks with verifiable answers (math, code, constrained generation), start with a small best-of-N baseline and report the full setup: , sampling temperature, verifier, wall-clock budget, pass@1, pass@N, selected accuracy, and failure cases. Do not publish a universal default sample count. The right budget depends on base pass rate, verifier quality, latency, and benchmark difficulty.
What To Report Before Claiming A Gain
The recurring mistake in test-time-compute papers is to report only the best selected accuracy. A serious comparison should include:
| Quantity | Why it matters |
|---|---|
pass@1 | tells you what the base model can do without search |
pass@N or candidate diversity | shows whether extra samples actually uncover new correct paths |
| selected accuracy | measures what the verifier plus search procedure returns |
| verifier calls / rollout count | captures hidden compute beyond generated tokens |
| wall-clock latency and token budget | keeps the result tied to an actual deployment cost |
| failure cases | reveals whether gains come from better reasoning or better exploitation of the evaluator |
When Test-Time Compute Helps (and When It Doesn't)
Test-time compute is most effective when:
- The task has a reliable verifier (code execution, math provers)
- The model has a non-zero pass rate (it sometimes gets the answer right)
- The task requires multi-step reasoning (search helps explore paths)
Test-time compute is least effective when:
- Verification is as hard as generation (open-ended writing, subjective tasks)
- The model never produces correct answers (fundamental capability gap)
- The task is easy (single-pass generation already succeeds reliably)
Common Confusions
More tokens does not always mean better reasoning
Generating a longer chain-of-thought is not the same as reasoning more deeply. Models can produce long, fluent chains of text that arrive at the wrong answer. The quality of reasoning depends on the model's training, not just the length of the output. Structured search with verification matters more than raw token count.
Best-of-N is not the same as temperature sampling
High temperature increases output diversity but does not select for quality. Best-of-N generates diverse candidates and selects the best one. The selection step is what matters. Without a good verifier, high-temperature sampling just produces more varied wrong answers.
Pass@N is not the same as selected accuracy
pass@N asks whether at least one correct solution appears among the
candidates. Selected accuracy asks whether the verifier-search system returns
the correct one. The gap between the two is a direct measure of verifier or
search weakness.
Test-time and train-time compute are not fully substitutable
A small model with massive test-time compute cannot match a large, well-trained model on all tasks. Test-time compute helps the model use knowledge it already has more effectively. It cannot inject knowledge the model never learned. The substitution works for reasoning tasks where the knowledge is present but the inference path is hard to find.
Summary
- Test-time compute scaling: generate multiple candidates and select the best
- Best-of-N with a verifier: success probability
- PRMs guide search at each step; ORMs score only the final answer
- MCTS adapts game-playing search to reasoning traces
- Chain-of-thought provides serial compute via intermediate tokens
- Latent reasoning trades visible tokens for internal computation
- Verifier quality is the bottleneck: poor verifiers lead to inference-time reward hacking
- Reported scaling curves are benchmark-, model-, method-, and verifier-dependent
Exercises
Problem
A model solves a math problem correctly with probability per attempt. Using best-of-N with a perfect verifier, how many samples do you need to achieve a 95% probability of finding at least one correct solution?
Problem
Compare the compute efficiency of two strategies: (A) train a 2x larger model and generate one response; (B) keep the original model and use best-of- with a perfect verifier. In a toy model, assume training scaling gives accuracy and best-of-N gives accuracy with fixed per-sample cost, under what conditions does strategy B dominate?
Problem
The inference-time reward hacking problem: as increases in best-of-N with an imperfect reward model, the selected response increasingly exploits the reward model rather than improving in true quality. Formalize this using the Gao et al. (2022) framework: if the proxy reward and the true reward have correlation , how does the expected true reward of the best-of-N selection behave as ?
References
Canonical:
- Cobbe et al., "Training Verifiers to Solve Math Word Problems" (2021). Outcome verifiers and rejection sampling for math word problems.
- Wei et al., "Chain-of-Thought Prompting Elicits Reasoning in Large Language Models" (2022). Prompting visible intermediate reasoning.
- Wang et al., "Self-Consistency Improves Chain of Thought Reasoning in Language Models" (2022). Majority-vote selection over sampled CoT chains, the canonical no-verifier baseline.
- Lightman et al., "Let's Verify Step by Step" (2023). Process supervision for mathematical reasoning.
- Yao et al., "Tree of Thoughts: Deliberate Problem Solving with Large Language Models" (NeurIPS 2023). Search over intermediate reasoning units.
Current:
- Snell et al., "Scaling LLM Test-Time Compute Optimally Can Be More Effective Than Scaling Model Parameters" (2024). Compute-aware inference scaling and prompt-dependent allocation.
- DeepSeek-AI, "DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning" (2025). Public report on RL-trained reasoning behavior.
- Gao et al., "Scaling Laws for Reward Model Overoptimization" (2022). Proxy reward overoptimization under best-of-N and related selection pressure.
- Xie et al., "Monte Carlo Tree Search Boosts Reasoning via Iterative Preference Learning" (2024). MCTS-style search for reasoning with iterative preference updates.
Next Topics
The natural next steps from test-time compute:
- Reward models and verifiers: the signals that guide test-time search
- Post-training overview: how models are trained to support test-time reasoning
Last reviewed: April 26, 2026
Canonical graph
Required before and derived from this topic
These links come from prerequisite edges in the curriculum graph. Editorial suggestions are shown here only when the target page also cites this page as a prerequisite.
Required prerequisites
2- Scaling Lawslayer 4 · tier 1
- Agentic RL and Tool Uselayer 5 · tier 2
Derived topics
4- Inference-Time Scaling Lawslayer 5 · tier 2
- Latent Reasoninglayer 5 · tier 2
- Post-Training Overviewlayer 5 · tier 2
- Reward Models and Verifierslayer 5 · tier 2
Graph-backed continuations